



von Dr. William Sen
digitalwelt-Kolumnist für strategisches Social Media Management
![]()
Wenn ein mittelständisches Unternehmen zwanzig neue Beiträge im Monat über sich im Web findet, ist es in der Lage, jeden einzelnen davon auszuwerten. Ein Know-how für die Community einmal vorausgesetzt, kann das Unternehmen intellektuell abschätzen, welche Reichweite und Konsequenzen die einzelnen Beiträge haben.
Werden aber Meinungen über Unternehmen, wie beispielsweise über die Deutsche Telekom oder BMW verbreitet, hat man es mit einer schier unendlichen Fülle an Daten zu tun. Eine Analyse der Reichweiten solcher Daten stellt also demnach ein Problem dar. Zum ersten Mal veröffentlichen die Heinrich-Heine-Universität Düsseldorf und die Technische Hochschule Köln ihre Ergebnisse zur Messung von Social Media Reichweiten.
Allein über BMW erscheinen täglich mehr als 10.000 Beiträge im Netz. Alle diese nutzergenerierten Inhalte mit menschlicher Power auszuwerten, scheint unmöglich zu sein. Eine künstliche Intelligenz, die innerhalb des Social Media Monitoring als Sentiment-Analyse bekannt ist, wird hingegen kritisch betrachtet, da sie häufig verfälschte Ergebnisse liefert, auf deren Basis keine Entscheidungen gefällt werden können.
Einige Ansätze in der Meinungsforschung stießen allerdings sehr wohl auf Zustimmung. So wurde im Social Media Monitoring beispielsweise die Idee entwickelt, nur diejenigen Beiträge auszuwerten, die tatsächlich eine hohe Reichweite besitzen. Damit werden nur jene Beiträge beobachtet, die für eine hohe Streuung im Web sorgen, als Trendmacher gelten und somit die breite Meinung beeinflussen. Im Trendmonitoring sind solche Ansätze durchaus höchst interessant. Auf diese Weise können Unternehmen aus einer großen Menge an Daten sofort erkennen, welche Themen für großes Interesse sorgen und erfassen damit sogar zukunftsweisende Trends und Themen. In der Praxis fehlten allerdings bislang Konzepte und Methoden für Social-Media-Measurement, die eine derartige Auswertung überhaupt ermöglichen.
Problemstellung
Die grundsätzliche Frage, die aus der Forschung hervorgeht, ist folgende: „Würde man einen Social-Media-Experten damit beauftragen, die Reichweite eines Beitrags in einem Forum zu messen, wie würde er vorgehen?“
Die Antwort darauf scheint auf den ersten Blick naheliegend zu sein. Der Social-Media-Experte würde höchstwahrscheinlich den Beitrag lesen und das Thema intellektuell erfassen, kurzum: Er würde zunächst einmal verstehen, über was dort überhaupt diskutiert wird. In den nachfolgenden Schritten müsste sich der Experte schließlich die Kompetenzen eines Information Brokers aneignen. Er würde somit in sämtlichen Social-Media-Quellen, wie Blogs, Foren und Social Media Networks, recherchieren, ob das Thema eine Verbreitung gefunden hat. Wenn beispielsweise zahlreiche Videos bei YouTube veröffentlicht wurden, das Thema genügend Retweets bei Twitter erhalten und eine rege Diskussion in sämtlichen Blogs und Foren stattgefunden hat, würde der Social-Media-Experte wohl davon ausgehen, dass der Beitrag eine hohe Reichweite erreicht hat.
Ein geschulter Social-Media-Experte würde sogar noch einen Schritt weitergehen und untersuchen, in welchem Zeitraum die jeweilige Verbreitung stattgefunden hat. Er könnte daraufhin den Verlauf der Streuung grafisch aufbereiten, von welcher Quelle die Nachricht zur nächsten Quelle „gesprungen“ ist. Das Ergebnis wäre ein chronologischer Verbreitungsweg einer Botschaft oder Diskussion. Soweit die Theorie. An solchen naheliegenden Antworten haftet allerdings ein beliebtes Vorurteil: Die Ergebnisse seien schlichtweg falsch. Auch wenn die Vorgehensweise des beschriebenen Beispiels sicherlich nicht völlig verkehrt ist, lässt sie sich nicht auf die Praxis übertragen. Das Problem hierbei ist zunächst, dass Marktforscher selten an der Reichweite von einzelnen Beiträgen interessiert sind. Im Grunde möchte man vielmehr unter Millionen von Nachrichten ausnahmslos alle nach ihrer hohen Reichweite analysieren können. Die Ansprüche sind also weitaus höher als zunächst angenommen.
Die intellektuelle Vorgehensweise des Social-Media-Experten im beschriebenen Beispiel kann sich jedoch nicht auf mehrere Beiträge ausweiten. Zumindest hätte er große Zeitprobleme, wenn er sein Verfahren auf 3.000 oder gar Millionen Beiträge übertragen müsste. Selbst mit einem ausgeklügelten Prozess würde der Experte mehrere Jahre brauchen, um jeden einzelnen Beitrag intellektuell verstehen, zurückverfolgen und auswerten zu können. Allein in einem einzigen Forum können täglich mehr als 10.000 Beiträge publiziert werden.
Diese Problemstellung vor Augen gebracht, bleibt im Grunde nur noch ein Lösungsweg übrig: Reichweiten müssen automatisch ausgewertet werden können. Das bedeutet jedoch, dass eine Software in der Lage sein muss, aus einem geschrieben Text, sei es in einem Forum oder Blog, eine Reichweite und sogar eine „Gefahr für die Verbreitung“ zu erkennen.
Das Forschungsprojekt „Social Media Measurement“ ging genau dieser Frage nach. Das Ergebnis ist eine Methode, die alle zur Verfügung stehenden Technologien ausnutzt, um am Ende eine solche automatische Auswertung möglich zu machen.
Der Weg dahin ist keineswegs mit künstlicher Intelligenz bzw. Sentiment-Analyse zu erreichen, welche in der Auswertung von User Generated Content ohnehin oft scheitert und von Sprachwissenschaftlern stark kritisiert wird. Ein Computer ist nun einmal nicht in der Lage, Gefühle in Texten zu erkennen, geschweige denn aufgrund des Inhaltes zu urteilen, ob eine Nachricht für die Gesellschaft wichtig ist oder nicht.
Der Fokus der Wissenschaftler war daher sehr pragmatisch. In der Marktforschung bekannt als Data Mining, lassen sich bereits bekannte Modelle, beispielsweise aus der Nachrichtenforschung und Diffusionsforschung, auch auf Social Media übertragen. Das Ergebnis sind im Grunde Kennzahlen, die aus nichts anderem bestehen als Algorithmen. Nach mehr als zwei Jahren Forschung sind die Ergebnisse schließlich ebenso überraschend wie erfreulich. Die Forschungsergebnisse stammen dieses Mal nicht aus den USA, dem Erfinder des Web, sondern aus einer Konstellation der Universität Düsseldorf, der Technischen Hochschule Köln und dem deutschen Marktforscher infospeed.
Forschungsergebnisse
Das Modell zur Erfassung des Social Web wurde innerhalb der Forschungsreihe bereits im Jahre 2004 durch Prof. Dr. Matthias Fank am Institut für Informationswissenschaft der Technischen Hochschule Köln entwickelt.
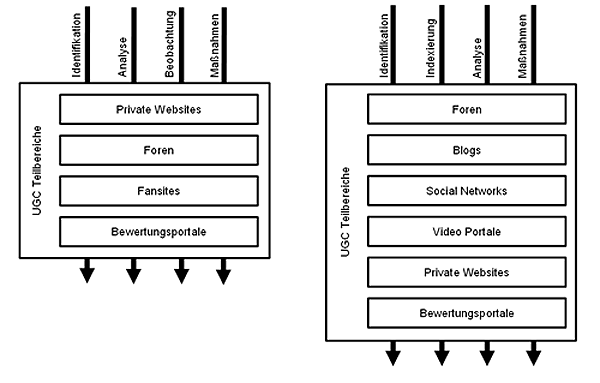
Erfassung des Social Web nach Fank (2004)
Dieses Modell diente als ein wesentliches Aufbauelement für die vorliegende Forschung, auch wenn damals die Frage nach Social-Media-Reichweiten noch nicht aktuell war. Es gab jedoch ein wichtiges Konzept frühzeitig vor.
Hiernach ist die Erfassung des gesamten Webs ohne eine Unterteilung der jeweiligen Quellen unerlässlich. Statt das Web also als ein Gebilde zu betrachten wird empfohlen, sich nur auf bestimmte und definierte Teilbereiche zu konzertieren, die User Generated Content (UGC) beinhalten. Somit geht Fank in seinem Modell im Grunde davon aus, dass jeder Teilbereich speziell handzuhaben ist. Die verschiedenen Teilbereiche des Social Web variieren in ihren Umgebungsvariablen und nach seiner Ansicht haben zum Beispiel Foren grundsätzlich andere Merkmale als Bewertungsportale
Fank geht zunächst davon aus, dass zum Auffinden der jeweiligen Quellen bestimmte Suchalgorithmen zum Einsatz kommen müssen. Für das Auffinden von Foren wird beispielsweise eine Art Identifikation betrieben, heute immer bekannter als Social Media Audit. Diese beschränkt sich unter anderem auf Foren-Software und weitere forenspezifische Merkmale. Somit ist es in einem professionellen Research auch möglich, sich die Expertise zu jedem Teilbereich anzueignen, um darin Information Retrieval betreiben zu können.
Auf diese Weise gestaltet sich die Recherche in einem Bewertungsportal grundlegend anders, als beispielsweise die Suche in einem Forum.
Im Jahre 2008 wurde das Modell um Blogs, Video-Portale und Social Networks erweitert. Laut Fank ist nach diesem Modell eine Erweiterung der jeweiligen Teilbereiche möglich und sogar aufgrund der Veränderung des Webs erforderlich.
Social Media Scorecard
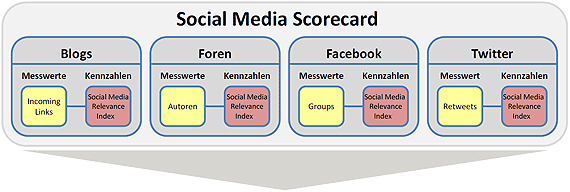
Um herauszufinden, wie sich Reichweiten in Social Media messen lassen, wurde aufbauend auf dem ersten Modell zur Erfassung des Social Web ein Modell namens Social Media Scorecard (Fank & Sen, 2010) entworfen. Die Social Media Scorecard teilt ebenfalls Social Media in seine Teilbereiche auf, diesmal allerdings mit dem einzigen Ziel, Reichweiten einzelner Nachrichten darin messbar zu machen.
Der wesentliche Unterschied der Scorecard gegenüber dem Modell der Erfassung ist allerdings, dass Portale wie Twitter und Facebook nicht mehr in die Kategorie Blog und Social Network fallen, sondern als einzelne Teilbereiche differenziert werden. Hinzu kommt, dass für jede dieser Quellen spezielle Vorgehens- und Betrachtungsweisen definiert wurden, die wiederum Kennzahlen zur Ermittlung der Reichweiten erhalten.
Um beispielsweise die Reichweite eines Tweets in Twitter zu messen, müssen nach Fank & Sen die Retweets als Variablen mit Hilfe einer Formel ausgewertet werden. Das Ergebnis ist eine errechnete Zahl, die die Reichweite konkret angibt und als Social Media Relevance Index bezeichnet wird.
Nicht-Indikatoren
In zahlreichen Forschungsprojekten sind die Besucherzahlen bzw. die Visits in einer Social-Media-Quelle, wie beispielsweise in einem Forum, hinreichend diskutiert worden.
Für Reichweiten-Analysen sind die Visits für ein Posting oder Thread allerdings ungeeignet, was das Forschungsprojekt der Technischen Hochschule Köln im Laufe zahlreicher empirischer Untersuchungen feststellte. Hierfür sprachen zwei wichtige Gründe: Zum einen zeigten die Untersuchungen, dass Diskussionen mit einem für den Nutzer interessanten Titel hohe Klickzahlen aufzeigen. Der Nutzer selbst erfährt jedoch erst nach dem Klick, ob der Inhalt für ihn wirklich von Interesse ist oder nicht. Ist der Inhalt uninteressant, verlässt der Nutzer den Thread. Der Klick wird jedoch trotzdem als Visit gezählt. Vielerlei Themen, wie beispielsweise Anleitungen, News- und Update-Meldungen, sorgen jedoch für hohe Klickraten. Weiterhin sorgen auch plakative oder provokante Themen für hohe Klicks, wenn zum Beispiel im Titel Begriffe wie „Sex“ oder ähnliches vorkommen.
Eine Unverhältnismäßigkeit zwischen Visits und Reichweite wurde vor allem in Foren erkannt, in denen Besucherzahlen öffentlich angezeigt werden. Auch ohne eine empirische Untersuchung lässt sich bereits erkennen, dass Themen mit hohen Visits von 2.000 und mehr Klicks durchaus weniger als 2 Antworten haben können, während dagegen Themen, die unter 300 Visits besitzen, durchaus für mehr als 30 Antworten sorgen können.
Eine empirische Untersuchung von mehr als 20 Foren an der Universität Düsseldorf ergab, dass diese These zutrifft. Die folgende Grafik zeigt sehr deutlich, dass kaum oder gar kein Zusammenhang zwischen Anzahl der Visits und Anzahl der Antworten in einem Thread besteht.
Im späteren Verlauf der Untersuchung stellte das Forschungsteam der Universität Düsseldorf sogar fest, dass virale Effekte aus Foren entstanden sind, die anfangs nur wenige Visits besaßen. Es musste daher davon ausgegangen werden, dass diese wenigen Klicks von sogenannten Opinion Leadern und Heavy Usern verursacht wurden, die die Nachricht von der ursprünglichen Quelle in die breite Masse getragen haben. Hätte in einem solchen Fall die Anzahl der Visits als Indikator für die Reichweite gedient, wäre diese Diskussion in einer Reichweiten-Analyse als unwichtig eingestuft worden.
Zum anderen können Visits nicht als Reichweiten-Indikatoren verwendet werden, weil die meisten Foren ihre Besucherzahlen gewöhnlich nicht offenlegen. Nur die Betreiber der Foren selbst sind in der Lage, aufgrund installierter Statistik-Tools derartige Messungen vorzunehmen. Es ist unnötig zu sagen, dass es einem Analysten bei der Analyse von hunderten von Foren nicht möglich ist, alle Forenbetreiber aufzufordern, ihre Statistiken offenzulegen. Es mussten also schließlich Indikatoren definiert werden, die erstens vorliegen und zweitens ohne einen höheren technischen Aufwand messbar sind. Im Verlauf der Forschung wurden darüber hinaus nur Indikatoren gewählt, die einen Zusammenhang zur Reichweite eines Beitrags in einem Social-Media-Kanal, sei es Forum oder Blog, messen sollen. Die grundlegende Idee des Forschungsprojektes blieb jedoch, nur diejenigen Indikatoren als Messwerte aufzunehmen, die automatisch und somit mit Technologien gemessen werden können.
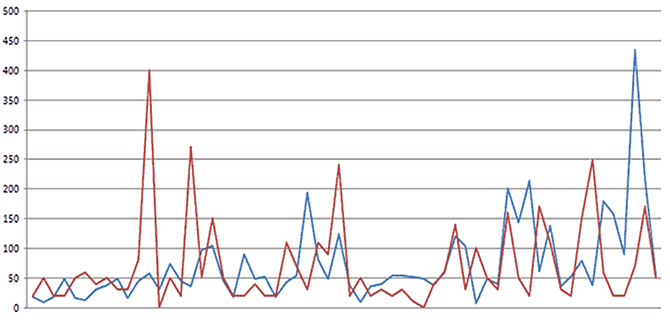
Anzahl Besucher / Anzahl Replies (in einem Themenbereich)
Das Forschungsteam der Heinrich-Heine-Universität Düsseldorf identifizierte über 40 virale Themen, die im Web für eine hohe Verbreitung gesorgt hatten. Dabei wurde zwischen bereits stattgefundenen und aktuellen Themen unterschieden. Die Verbreitung aller Themen auf andere Foren wurden zunächst intellektuell gemessen und die jeweiligen Themenbereiche zur Messung vorgemerkt. Die gleiche Anzahl von Themen wurde für nicht-virale Themen identifiziert, um einen direkten Vergleich zu erzielen. Um schließlich die Wertbarkeit externer Technologien zu prüfen, wurden die Technologien zunächst alle bei der Gewinnung von Daten angewendet. Daraufhin konnten diejenigen Technologien, die keine zusammenhängenden Daten oder nur willkürliche bzw. unbrauchbare lieferten, von der Nutzung ausgeschlossen werden. Das Ergebnis war eine Auswahl von externen Technologien, die tatsächlich in der Lage sind, wertvolle Daten zur Erstellung von Kennzahlen zu liefern.
Ausrechnung einer Relevanz
von Dominik Grimm und Dr. William Sen
In einem früheren Schritt setzte sich die Forschung damit auseinander, eine Relevanz-Kennzahl von Foren in einer Skala von 1 bis 10 auszurechnen (Grimm, 2009).
In einer ersten Forschungsreihe im Rahmen der Technischen Hochschule Köln am Institut für Informationswissenschaften, wurden bei der Entwicklung des Modells zunächst deutschsprachige Foren in Deutschland ermittelt, die nach bestimmten Kriterien in einem „Master Sheet“ (Fank et al., 2006) bewertet wurden. Um die Anzahl der Foren durchschaubar zu halten, wurden Foren aus der Automobilbranche ausgewählt. Das Ziel bestand darin, einen Algorithmus zu entwickeln, dessen Ergebnis eine erste Kennzahl zur Reichweiten-Bestimmung von Foren und deren Beiträgen sein sollte.
Es wurde zunächst die These aufgestellt, dass nur diejenigen Foren auch eine Reichweite besitzen, die bestimmte interne und externe Merkmale erfüllen. Zu den internen Merkmalen zählten beispielsweise Indikatoren wie „durchschnittliche Antwortzeit auf einen Beitrag“, „Anzahl Autoren“ oder „Anzahl Beiträge“. Als externe Indikatoren wurden bereitstehende Technologien verwendet, die Merkmale wie „Link Popularity“, „Trackbacks“ und „Rank“ aufgrund eigenen, allerdings nicht öffentlichen Algorithmen ausrechnen konnten. Um einen Höchstpunkt zu setzen, wurden die jeweils größten Foren verwendet, die bereits in zahlreichen Social Media Audits von dem Marktforschungsinstitut infospeed ermittelt wurden. Demnach wurde das größte deutschsprachige Automobilforum motor-talk.de mit dem Relevanzwert R = 10 als Ausgangspunkt festgesetzt.
Um hingegen die Reichweite eines Beitrags zu bestimmen, bestand der Ansatz darin, die Reichweite eines Threads innerhalb des eigenen Forums autark zu bestimmen. In diesem Fall wurden weitere Indikatoren als Messwerte benutzt, wie unter anderem „Anzahl der Beiträge eines Autors“, „Anzahl der verschiedenen Autoren, die sich in einem Thread beteiligt haben“, „Zeitspanne der Beiträge“ oder „Menge der Beiträge“. Bei der Beurteilung der Reichweite wird hier der Indikator Visits, wie bereits oben beschrieben, ebenfalls außer Acht gelassen und mit der Annahme begründet, dass Nutzer erst durch das Lesen des Beitrages die Entscheidung über eine persönliche Relevanz für das Thema treffen. Es sind die Autoren eines Beitrags oder Threads, die in der Ermittlung der Beitragskennzahl eine entscheidende Rolle spielen.
In der Ergebnisdarstellung konnte zu jedem der Indikatoren eine grafische Darstellung erstellt werden. Die folgende Grafik zeigt beispielsweise, wie sich die Quantität (Anzahl von Pages in einem Forum) auf die Anzahl von 50 Foren verteilt.
Das Ergebnis der empirischen Untersuchung waren schließlich mehrere Relevanz-Kennzahlen, die daraufhin in einer einzige Kennzahl mündeten.
Im folgenden Beispiel kann bei einer Kennzahl über dem Wert 5 davon ausgegangen werden, dass ein erhöhtes Interesse an einem Thread besteht. Durch die externen Werte, die hinzugezogen werden, wird deutlich, dass der Beitrag auch außerhalb des Forums eine hohe Reichweite erzielt. Derartige Ergebnisse lassen annehmen, dass Themen über der Relevanz-Skala 5,0 inhaltlich auf eine große Motivation schließen lassen und der Beitrag somit für die Community von Bedeutung ist.
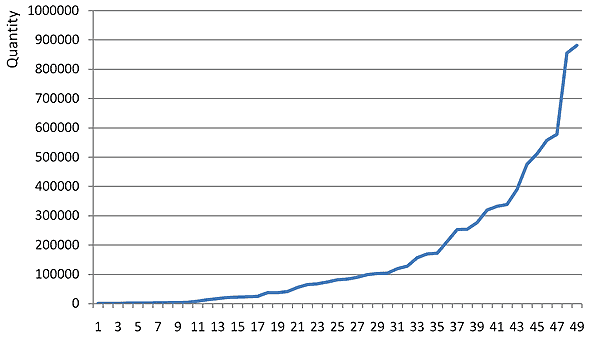
Anzahl von Pages in einem Forum
Bei der Ermittlung spielte es zudem keine Rolle, ob nun 10 oder 1.000 Beiträge in einem Thread identifiziert wurden. Die Abweichung der Autorenanzahl bei steigender Beitragsmenge wird vor der Ermittlung der Beitragskennzahl linear und forenspezifisch berechnet und führt somit zu einem klaren Ergebnis.
Die Kombination der beiden Messwerte Foren- und Beitragskennzahl gibt schließlich einen endgültigen Aufschluss über die Reichweite eines einzigen Beitrags in einem Forum.
Mitgliederzahlen automatisch erkennen
Nachdem auf einer 10-stufigen Skala zunächst Foren anhand automatisiert ermittelter Relevanzwerte – aus vorausgegangenen Forschungsergebnissen der Nachrichtenforschung – in eine relative Verbindung gebracht wurden, konnten auf dieser Grundlage auch weitere Daten statistisch ausgewertet und gewichtet werden.

Relevanzskala 1-10
Bereits zu diesem Zeitpunkt der Forschung war klar, dass die dabei genutzten einzelnen Variablen bzw. Indikatoren sowohl die Reichweite, als auch die Relevanz in den jeweiligen Foren berücksichtigt hatten.
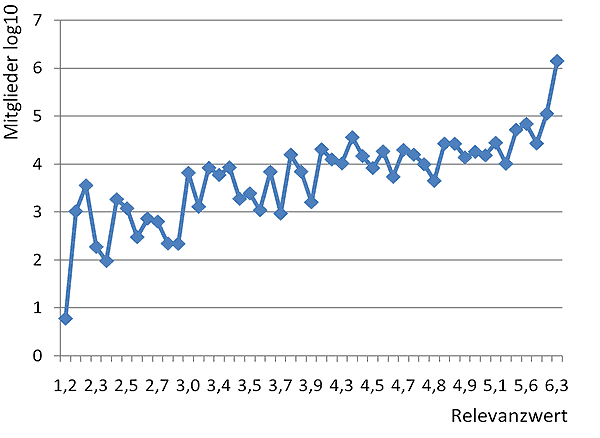
Das Ergebnis brachte in der weiteren Auswertung eine zusätzliche, wichtige Eigenschaft mit sich: Aufgrund der empirischen Daten war es schließlich möglich, nicht nur Reichweiten zu bestimmen, sondern auch Mitgliederzahlen von Foren zu berechnen, auch wenn diese in den Foren nicht ausgewiesen werden. Hierzu wurden alle ausgewerteten Foren mit den jeweiligen Relevanz-Kennzahlen den jeweiligen Mitgliederzahlen zugeordnet:
Formel zur Ermittlung der Abweichung von der durchschnittlich zu erwartenden Autorenzahl.
Je größer die Relevanz eines Forums, desto mehr steigt auch die Mitgliederzahl in den jeweiligen Foren. Dies verdeutlicht sich unter anderem in dieser Auswertung. Aus dieser Erkenntnis heraus und aufgrund der vorliegenden Daten wurde in einem nächsten Schritt eine Formel zur Messung von Mitgliederzahlen durch Relevanzmessung entwickelt:
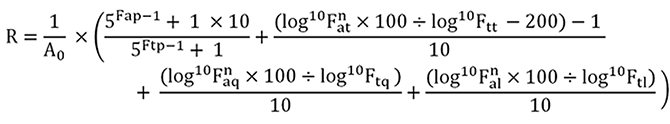
Ein großer Teil der ausgewählten Indexwerte wird innerhalb der Formel logarithmiert, um die Vergleichbarkeit der Daten zu gewährleisten und eine Zusammenführung zu ermöglichen. Im oben abgebildeten Beispiel werden 4 Bewertungsfaktoren, die einer vorherigen Gewichtung unterzogen wurden, in Verbindung gebracht und bilden im Endergebnis den Reichweitenindex „R“. Die Formel zeigt die Zuordnung der indexierten Unterseiten zu einer Foren-URL (Base URL). Dieser Wert fließt unter anderem in die Berechnung des Algorithmus mit ein. Der Grund, diesen Wert in die Berechnung aufzunehmen, liegt unter anderem in der Tatsache begründet, dass auch Suchmaschinen bei der Reihenfolge der Ergebnisdarstellung diesen Wert berücksichtigen. Somit ist die Erreichbarkeit und somit auch die Relevanz bzw. Reichweite eines Forums höher, wenn es bei öffentlichen Suchmaschinen hoch aufgelistet ist.
Mehrere stichprobenartige Beweisführungen zeigten, dass die Genauigkeit der Mitgliederzahlen bis auf wenige Ausnahmen mit einer Abweichung von ca. 10% übereinstimmt, obwohl nur Foren aus der Automobilbranche ausgewertet wurden. Zur Prüfung der Zahlen wurde die Suchmaschine web2monitor der Firma infospeed verwendet. Die Kennzahl ist übertragbar auf weitere Branchen.
In einer späteren Untersuchung der Heinrich-Heine-Universität Düsseldorf, in der mehr als 1.000 Foren in die Bewertung eingespeist wurden, fand diese Formel eine erneute Anwendung, um die Abweichungen auf deutlich unter 10% zu minimieren. Letztlich ist die Menge und Aktualität der zugrunde liegenden empirischen Daten dafür verantwortlich, wie genau die Bestimmung erfolgt.
Empirische Forschung
von Dr. William Sen
Ein weiterer Forschungsansatz der Universität Düsseldorf bestand darin, die bereits aus der Automobilbranche vorliegenden Modelle und Formeln auf das gesamte Spektrum der deutschsprachigen Foren auszuweiten, um branchen-unabhängig Reichweiten-Analysen durchführen zu können.
Hierzu wurde erneut das Marktforschungsunternehmen infospeed hinzugezogen, das mit dem Einsatz der Social Media Scorecard und anhand der vorliegenden Ergebnisse bereits Erfahrungen im praktischen Einsatz mit deutschen Unternehmen gesammelt hatten.
In dieser Arbeitskonstellation wurde zunächst die wesentliche Zielsetzung konkreter definiert, um messbare Variablen und eine Ermittlung von Kennzahlen gestalten zu können: Es sollte möglich sein, entweder mit vollautomatischen oder halbautomatischen Methoden einen eindeutigen Relevance Index erstellen zu können. Nur auf diese Weise können softwaregestützte Systeme zum Einsatz kommen, die Reichweiten „auf einen Klick“ berechnen können, ohne dass aufwändige intellektuelle Analysen durchgeführt werden müssen.
Weiterhin wurde der Begriff Reichweite klarer ausformuliert und unter anderem nach dem Ansatz von Prof. Dr. Wolfgang G. Stock in Verbindung mit „Potenzial zur viralen Verbreitung“ gebracht. So betrachtet beinhaltet die Ermittlung einer solchen Kennziffer auch eine Frühwarnfunktion bezüglich einer möglichen Verbreitung im Sinne eines viralen Effekts im Netz.
Die Methode, Reichweiten zu analysieren, ist zumindest in den klassischen Nachrichtenkanälen im Grunde nicht neu. In der Nachrichtenforschung, der PR-Evaluation und sogar in der Innovationsforschung beschäftigen sich Wissenschaftler seit längerer Zeit mit der Ermittlung der Verbreitung und Wirkung von Nachrichten mit Hilfe von Kennzahlen. Einen nicht unwesentlichen Teilbereich dieser Forschung stellt beispielsweise die Diffusionstheorie dar. Somit wurden an der Universität Düsseldorf Kennzahlen aus den klassischen Forschungsgebieten in die einzelnen Teilbereiche der Social Media Scorecard hinzugezogen. Die Auswertung wurde schließlich auf mehr als 2.800 empirische Datensätze ausgeweitet, um weitere Kennzahlen zu entwickeln.
Social Media Empirical
Der Social Media Empirical der Universität Düsseldorf ist in der Lage, tausende Beiträge in Social-Media-Quellen zu sammeln, um sie schließlich mit Hilfe technologischer Mittel mit Kennzahlen zu bewerten.
Aus den empirischen Ergebnissen ist es möglich, mehrere Kennzahlen zu entwickeln. Im weiteren Verlauf soll der Social Media Empirical kontinuierlich mit neuen Daten aktualisiert werden, da die Social-Media-Landschaft ständigen Veränderungen unterliegt. Somit ist es möglich, und auch notwendig, die Kennzahlen an neue Werte anzupassen und somit zu aktualisieren.
Social Media Empirical / Heinrich-Heine-Universität Düsseldorf
Anwendungsgebiete
In der Marktforschung kommt der Messung von Social-Media-Reichweiten derweil vor allem im Bereich Social Media Monitoring eine hohe Bedeutung zu.
Da die meisten Anbieter ihren Kunden die Daten über ein Cockpit anbieten, ist die Darstellung von Reichweiten in solch einer Suche, in der Social-Media-Daten gefunden werden sollen, auf den ersten Blick am besten platziert. In einer großen Menge an Daten, die eine Diskussion über das Unternehmen beinhalten, hat dieses somit die Möglichkeit, sich nur die Daten mit hoher Relevanz anzeigen zu lassen. Auch Frühwarnsysteme werden dadurch möglich: Sobald ein Beitrag eine hohe Reichweite anzunehmen droht, kann beispielsweise eine Email auf diesen Thread hinweisen.
Das Marktforschungsunternehmen infospeed ist derzeit das einzige Unternehmen, das die Social-Media-Reichweiten automatisch über sein eigenes Cockpit nach der Scorecard ausrechnet und darstellt.
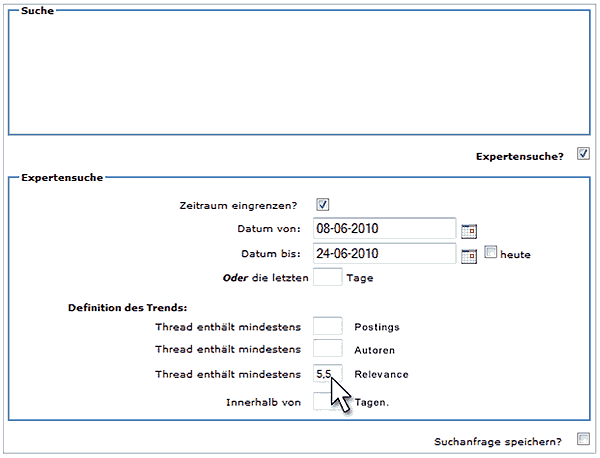
Social Media Cockpit des Social Media Monitoring Tools web2monitor
Aus den Suchtreffern aus Foren und Blogs ist es beispielsweise möglich, sich mit nur einem Klick auch eine Relevanz des Beitrags ausrechnen zu lassen. Somit kann ein Unternehmen erkennen, ob der Beitrag eine hohe Reichweite besitzt oder nicht. Weitere Anwendungsmöglichkeiten machen es möglich, dass in einer Datenmenge von mehreren Millionen Daten nur diejenigen Social-Media-Daten angezeigt werden, die eine hohe Reichweite besitzen. So kann ein Unternehmen aus einer großen Fülle von Daten nur eine kleine Schnittmenge herausfiltern und sehen.
Thread Relevance Index
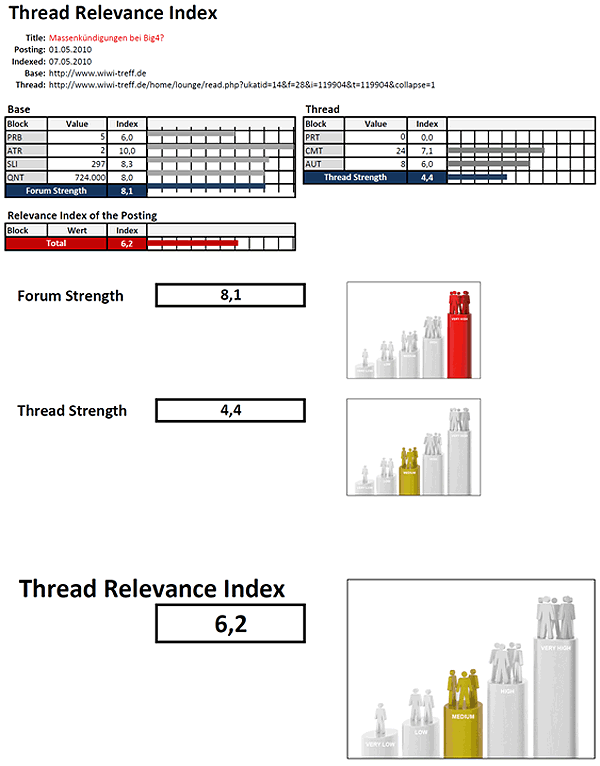
Thread Relevance Index
Vor allem im Alerting spielt die Reichweitenmessung in Social Media eine große Rolle. Unternehmen können, wenn sie sofort über Themen- oder Produktdiskussionen mit hoher Reichweite informiert werden möchten, durch ein Frühwarnsystem Reports per Email erhalten.
Dr. William Sen
Dr. William Sen ist u. a. Gründer des ersten staatlich zertifizierten Lehrgangs zum Social Media Manager (TH Köln) sowie Chefredakteur des ersten Social Media Magazins in Deutschland.
Als Lehrbeauftragter lehrte er u. a. an der TH Köln in den Bereichen Social Media Management, eEntrepreneurship, Digital Publishing, Communication Controlling und strategisches Marketing. Dr. William Sen lebt und arbeitet in San Diego, Kalifornien.
digitalwelt-Kolumnist für strategisches Social Media Management
![]()
Quellen
- Fank, M.; A. Bozjeloye; J. Dehne; M. Flocke; T. Kindler; H. J. Park; N. Raffiti; G. Todeva; A. v. d. Hoogen (2006): Ergebnisbericht Social Media Monitoring 2005-2006, 24.01.2006, Technische Hochschule Köln, S. 109-116, S.157-158.
- Grimm, D. (2010): Konzept zur Relevanzbestimmung von Internetforen und deren Beiträge am Beispiel der Automotive Industrie, Technische Hochschule Köln, Fakultät für Informations- und Kommunikationswissenschaften, 04.2010.
Forschungsteam Technische Hochschule Köln
- Prof. Dr. M. Fank (Technische Hochschule Köln, Institut für Informationswissenschaft)
- Dipl. Inf.-Wirt. D. Grimm (Technische Hochschule Köln, Forschungsreihe Relevanz in der Automobilbranche)
- Dipl. Phys. A. Kirsch (Kennzahlen und Algorithmen)
Forschungsteam Heinrich-Heine-Universität Düsseldorf
- Prof. Dr. W. G. Stock (Heinrich-Heine-Universität Düsseldorf, Leiter der Abteilung für Informationswissenschaft)
- Dr. W. Sen (Heinrich-Heine-Universität Düsseldorf, Forschungsleiter/-initiator)
- Y. Kaplan, G. Nativo (Portalidentifikation & Programmierung Social Media Empirical); O. Hanraths, S. Götz (Portalidentifikation & Programmierung Web Scraping); J. N. Keßler, R. Klein, K. Koch, S. Schmit (QM & Literatur); C. Baldauf, D. D.-Giustina, A. Diez, P. Hommers (Ermittlung von Kriterien); B. Ensan, D. Erdogmus, Y. Yildiz, I. Annouri, A. Abarkan, R. Kochanek (Reichweiten-Definitionen); H. Schweigert, N. F.-Brauer, K. Hauk, A. Schamber (Nachrichtenforschung/-werttheorie)
Methoden zur automatischen Reichweitenmessung von Beiträgen in Webforen

Forschungsleiter: Dr. William Sen
Wissenschaftliche Betreuer: Prof. Dr. Wolfgang G. Stock
Hochschulen: Heinrich-Heine-Universität Düsseldorf
Partner: infospeed GmbH
Veröffentlichungen: Social Media Measurement, Social Media Verlag, ISBN: 978-3941835238
Diese Forschung beschäftigt sich mit der Erstellung eines Konzepts zur automatischen Messung von Reichweiten einzelner Posts in Social Media mit dem Schwerpunkt Webforen. Die wesentliche Fragestellung ist: Kann man automatisch auswerten und aufzeigen, wann ein Beitrag in einem Webforum eine hohe Reichweite erreicht hat oder erreichen wird? Die Ergebnisse sind Methoden, die solche Messungen automatisch vornehmen können, ohne dass Nachrichten von einem Menschen oder von einer Maschine intellektuell oder automatisch gelesen werden müssen.
Hintergrund dieses Vorgehens ist der, dass in Social Media eine sehr hohe Anzahl von User Generated Content zu verschiedenen Themen vorhanden ist. Im weiteren Verlauf dieser Forschung wurde vor allem auch aufgezeigt, wie ein solches Konzept technisch umsetzbar ist. Daher wurden Inhalte von Webforen zunächst aufbereitet, um dann verschiedene Methoden mit Hilfe einer speziellen Software darauf anzuwenden.
Diese Erkenntnis führt dazu, dass sich Unternehmen aus einer großen Anzahl von Beiträgen im Social Web diejenigen anzeigen lassen können, die das Potenzial haben, eine hohe Reichweite zu erreichen oder bereits erreicht haben. Das bedeutet, dass beispielsweise Trends und Issues frühzeitig von Unternehmen erkannt werden können. Außerdem erleichtert diese Methode Marktforschern und anderen Zielgruppen „die Suche nach der Nadel im Heuhaufen“.








