



von Dr. William Sen
digitalwelt-Kolumnist für strategisches Social Media Management
![]()
Betrachtet man die Social-Media-Inhalte im Web genauer, fällt eine wiederholende Ähnlichkeit auf. Fast alle diese Inhalte scheinen Entitäten zu besitzen.
Bei Entitäten handelt es sich um Werte wie „Autorenname“, „Datum des Postings“ und „Antworten“ bzw. „Replies“. Derartige Entitäten kommen in Webforen, Blogs, Social Networks wie Facebook und Twitter und vielen weiteren Kanälen im Social Web vor. Auch ohne die Benutzung des Webs, sind derartige Merkmale zu finden. Denn es gibt auch im Alltag einen Sprecher (Sender), einen Zuhörer (Senke) und eine Nachricht. Diese Werte können allerdings im Alltag logischerweise nicht flächendeckend gemessen werden, da in diesem Fall das Gesprochene, im Gegensatz zum Geschriebenen im Internet, unter gewöhnlichen Umständen nicht aufgezeichnet wird.
Social Media und George Orwell
Gehen wir mal davon aus, wir befänden uns in Georges Orwells dystopischem Roman „1984“ (vgl. Orwell, 1981). Alles Gesprochene würde mit Teleschirmen aufgezeichnet werden und jeder Mensch wäre klar identifizierbar.
Verständlicherweise hat George Orwell mit seiner dystopischen Idee, als er 1949 sein Roman veröffentlichte (Lipp-mann & Leide, 2004, 11), noch nicht vorhersehen können, dass in unserer heutigen Welt Dinge wie Data Mining und relationale Datenbanken existieren werden.
Die Idee, Muster innerhalb von erhobenen Daten zu erkennen, ist allerdings nicht neu. Sie geht sogar auf das 6. Jhd. v. Chr zurück . Die jetzige Anwendung im Management zum Zwecke der Marktforschung, Erhebung sowie Erkennung von Zielgruppen und Meinungsführern gibt es allerdings erst seit Anfang der 90er Jahre (vgl. Nisbet et al., 2009, 10ff).
Hätte Orwell derartiges Wissen über Data Mining bereits 40 Jahre zuvor besessen, hätte er vielleicht seine Welt im Roman noch weiter dramatisiert. In seinem Roman werden jedoch lediglich vordergründig die Observation und Identifikation von Einzelpersonen durch den sog. „Big Brother“ als Hauptmerkmale einer Überwachung geschildert. Mit einem derartigen Überwachungsapparat aus Teleschirmen, wie sie der „Big Brother“ im Roman einsetzt, wäre es allerdings auch möglich, Menschengruppen und Meinungscluster zu bilden. Es bedürfte im Grunde keiner Echtzeitüberwachung mehr, wie im Roman geschildert, sondern wichtig wäre lediglich eine Speicherung des Gesprochenen in einer Datenbank. Mit solch einer Möglichkeit ließen sich auch in Orwells Roman Trends, Gefahren und Chancen für und gegen jegliche Institutionen bzw. Interessensgruppen, Meinungsführer, geordnet nach Themen, identifizieren. Es bräuchte also keine Echtzeitüberwachung durch Menschen, sondern nur eine strukturierte Auswertung durch Maschinen.

Data Mining im 21. Jahrhundert
Kommen wir zurück in die Realität und in das 21. Jahrhundert unserer Zeit. Anders als in der dramatischen Darstellung Orwells teilen die Nutzer Informationen freiwillig mit anderen.
Die Datenspeicherung findet im Web in diversen Kanälen, mittlerweile als Social Web bekannt, statt. Eine Überwachung ist möglich, sobald sich die Überwachungstechnologie auf das Social Web anstatt auf das Gesprochene fokussiert.
In beiden Fällen, sowohl in Orwells Dystopie als auch in der realen Webumgebung von heute, ist es möglich, den Sender einer Nachricht, die Nachricht selbst und den Zeitpunkt der Nachricht zu identifizieren. Allerdings sind bestimmte Merkmale notwendig, um ein Data Mining auch tatsächlich durchführen zu können: Werte müssen gesammelt und geordnet in eine Datenbank eingespeist werden, bevor dort zielgerechte Abfragen ausgeführt werden können.
Hätte man das Phänomen Internet nicht, wäre man eventuell nicht auf die Idee gekommen, dass Werte wie „Auto-renname“ und „Datum des Postings“ wichtige Messgrößen sein können. Denn für das Gesprochene sind sie quasi nicht erfassbar. Manovich (2001) erkannte diese Möglichkeit der Extraktion von Daten aus dem Web bereits Anfang des 21. Jahrhunderts.
Für das Internet sind diese Messgrößen und ihre Speicherung Voraussetzung dafür, um letztlich eine Abfrage so zu formulieren, dass das Ergebnis die Wichtigkeit und Reichweite eines Postings automatisch errechnet. Derzeit beschäftigen sich viele Publikationen im Bereich Social Media Monitoring meist mit der Thematik, Nachrichten aufzufangen und über sie zu berichten (vgl. Gebracht, 2010, 229ff). Doch welche weiteren Grundlagen sind notwendig, damit ausgerechnet mit Entitäten eine relevante Messung für Unternehmen zielgerecht sein kann?
Die Entität
Entitäten im Web spielen für ein Social Media Measurement die wichtigste Rolle. Sie werden oft auch als Messwerte, Messgrößen oder Social Media KPIs bezeichnet.
Um Daten aus dem Web automatisch messen zu können, werden quantitative Werte aus dem Social Web benötigt. Diese Werte liegen im Web und auch insgesamt im Internet in Form von Entitäten vor und sind eine Voraussetzung für ein automatisches Social Media Measurement.
Die Einführung des Begriffs Entität geht auf das „Entity-Relationship Model“ zurück, abgekürzt „ER-Modell“ von Chen (1976, 9ff). Chen setzte sich zum Ziel, eine Begrifflichkeit einzuführen, die dazu dienen sollte, Beziehungen aus der realen Welt innerhalb der Informatik besser zu definieren. In der Informatik versteht man seither unter einer Entität einen einzelnen, individuellen und virtuellen Gegenstand, der eindeutig identifiziert werden kann und einen Bezug auf Gebilde der realen Welt hat. „Im ER-Modell werden Dinge der realen Welt (Entitäten, engl. Entities) mit ihren Bezeichnungen untereinander (engl. relationships) modelliert“ (Vogt, 2004, 148).
Die beiden Begriffe Objekt und Entität sind in der Informatik ähnlich. Allerdings muss ein Objekt, wie es in der Informatik als Begriff verstanden wird, keinen Bezug zur Realität haben, während eine Entität diesen Bezug besitzen muss (Chen, 1976, 9-39). In einer Datenbank sind beispielsweise Einträge wie „Peter Müller“, „Hamburg“ oder „24. Dezember“ durchaus Entitäten, da sie Werte darstellen, die einen direkten Bezug zur Realität haben. Einträge wie beispielsweise „14.15.6“ oder „8701e063fa“ dagegen können nicht als Entitäten bezeichnet werden und fallen in die Kategorie der „Objekte“, da sie als Bezeichnung immateriell oder abstrakt sind. „Entitäten haben Eigenschaften, die durch Attribute dargestellt werden; dasselbe ist auch für Beziehungen möglich“ (Vogt, 2004, 148). Nach dem ER-Modell von Chen lassen sich auch Social-Media-Quellen erkennen.
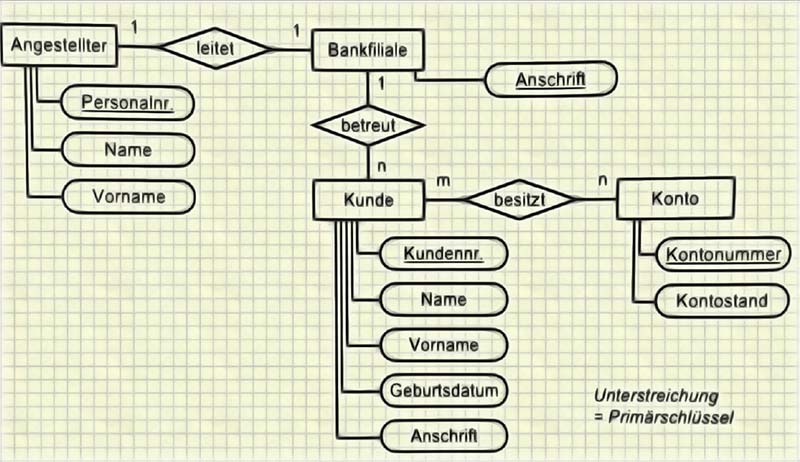
Beispiel für ein Entity-Relationship-Diagramm: Kreditinstitut mit Kunden (Vogt, 2004, 148)
Ob nun als Objekte oder als Entitäten bezeichnet, im Web und somit auch in Social Media finden sich Messwerte wieder, die grundsätzlich mathematisch bearbeitet bzw. logarithmiert werden können. In diesem Zusammenhang spricht Manovich (2001, 49ff) von „Numerical Representation“: Alle im Web vorliegenden Objekte können mathematisch beschrieben und einer mathematischen Formel zugeordnet werden. Das bedeutet, man kann mit diesen Werten Berechnungen anstellen.
Eine weitere Besonderheit digitaler Daten im Web liegt nach Manovich (2001, 55ff) in der Variability. Daten wie Texte liegen nicht unverändert und solide vor, wie beispielsweise in Printmedien, sondern können je nach digitaler Bearbeitung beliebig abgewandelt werden. Dadurch können sie für sehr viele verschiedene Datenbankabfragen verfügbar gemacht werden: „Variabilität ist die Voraussetzung für nutzerspezifische Parameter, sensitive Suchkriterien oder auch personalisierbare Interfaces. Zu den Grundlagen der Variabilität gehört neben den ersten beiden Prinzipien numerische Repräsentation und Modularität der digitalen Medien die Mediendatenbank […]“ (Michelis, 2010, 46).
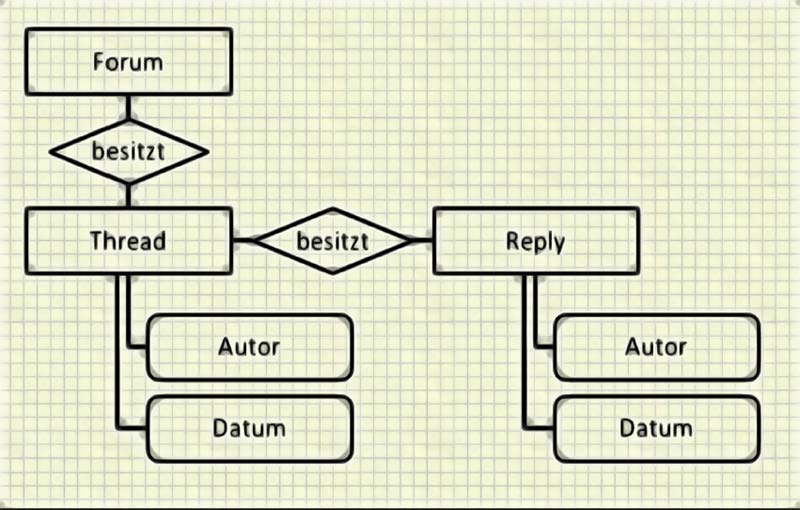
Beispiel für ein vereinfachtes Entity-Relationship-Diagramm für ein Webforum
Diese Erkenntnis bedeutet, dass in textlichen digitalen Daten, so auch in Social Media, Parameter und Informationen stecken, die man beide so extrahieren kann, dass sie in einer Datenbank gespeichert werden können und ein vollautomatisiertes Information Retrieval mit nur mathematischen und logarithmierten Abfragen ermöglichen. Diese Sichtweise ist bereits der wichtigste Hinweis darauf, dass automatische Messungen mit Hilfe von Messwerten, KPIs, somit also Entitäten, möglich sind.
Entitäten in Facebook
Facebook bezeichnet seine Entitäten als „Objects“. Insofern nutzt Facebook die allgemein verbreitete Bezeichnung der Informatik. Wie allerdings erkennbar wird, bestehen fast alle Objekte in Facebook eigentlich aus Entitäten.
Diese sind beispielsweise klassische Entitäten wie „Post“, „Kommentar“ und „Like“. Daneben bietet jedoch Facebook noch hunderte weiterer Entitäten an, wie beispielsweise „Link“, „Location“ (Ort des Facebook Users), „Anzahl Besucher“ (auf einen Kommentar oder Post), „Updated Time“ (wann ein Post geändert wurde), „Source“ (Quelle eines Teaser-Textes oder -Bildes).
Diese Entitäten sind nun nicht für alle Nutzer sichtbar, in den meisten Fällen sogar nicht einmal für den Ersteller der Nachricht. Doch aufgrund der von Facebook zur Verfügung gestellten APIs (Schnittstelle für Entwickler) ist es möglich, die von Facebook vergebenen Entitäten abzurufen. Facebook beschreibt eine seiner wichtigsten, zur Verfügung gestellten Schnittstellen als „Graph API“ (Kamleitner, 2012, 99). Sind erst einmal diese Entitäten erfasst, kann man je nach Unternehmens- oder Marktforschungsziel Daten auswerten. Man kann beispielsweise zu einem bestimmten Thema auswerten lassen, wie viele Menschen externe Links nutzen und wie viele eigene Inhalte erstellen. Somit könnte man herausfinden, ob ein bestimmtes Thema eher in Facebook selbst entstanden ist oder eher durch äußere Einflüssen auf Facebook diskutiert wird.
Entitäten in Twitter
Auch in Twitter lassen sich sehr viele verschiedene Entitäten erkennen. Neben den bei jedem Tweet sichtbaren 5 Entitäten „Tweet Account Name“, „Real Name“, „Tweet“, „Avatar“ und „Date“ gibt es noch viele weitere. Auch durch die von Twitter angebotene API, die letztlich aus mehreren APIs besteht (Sen, 2011), lassen sich somit weitere Objekte und Entitäten herauslesen. Über die sog. „Streaming API“ kann man beispielsweise folgende Entitäten direkt von der Twitter-Datenbank abfragen (Twitter Developers, o.D.):
Links
Links, die ein Tweet beinhaltet. Twitter erkennt einen Link u. a. automatisch daran, dass ein Tweet die Zeichen „http“ und „https“ enthält.
Retweet
Ein Reply wird bei Twitter „Retweet“ genannt. Allerdings beinhaltet ein Retweet bei Twitter nicht immer eine Antwort, wie beispielsweise in Foren oder E-Mails üblich. Sondern ein Retweet kann auch lediglich eine Wiederholung eines Tweets sein und ist somit gleichzeitig auch eine Art „Repeat“. Wenn ein Tweet von den Usern durch die Verwendung der „Retweet“-Funktion wiederholt wurde, kann Twitter diesen Beitrag bzw. Tweet als Retweet in seiner Datenbank erkennen, zum Beispiel wenn ein „RT“ in den Tweet eingefügt wurde. Dadurch sind auch Abfragen an die API möglich, um vorliegende Retweets auszuwerten. Auf diese Weise können Marktforscher durch die Nutzung dieser API erkennen, welche Nutzer von anderen Nutzern in welcher Häufigkeit retweetet wurden.
Tools, die auf diese Twitter-Schnittstelle zugreifen, können relevante Daten für Unternehmen darstellen. Derartige Tools sind nützlich beim Aufspüren von Personen, die die Meinung beeinflussen.
„Unternehmen, die sich in Social Media bewegen, sehen sich oft mit einer schier endlosen Zahl an Tweets, Postings, Bewertungen oder Kommentaren konfrontiert. Natürlich enthalten diese Texte wichtige Informationen, die für das Unternehmen von Relevanz sind. Um die Inhalte jedoch bestmöglich einordnen zu können, müssen auch Muster und Regelmäßigkeiten in den Beiträgen erkannt und infometrisch analysiert werden […]. Heavy User können beispielsweise anhand ihrer Verbindungen zu anderen Nutzern eruiert […] werden“ (Maisch, 2011).
Entitäten in Blogs
Paquet (2002) beschreibt ein Weblog als ein Online Journal, das mehr als nur Texte und Links beinhaltet, sondern auch andere Formen von Medien, z. B. Bilder und Videos. In der Regel beinhalten Blogs folgende Entitäten (vgl. ebd.):
- POST DATE (Datum und Zeit, wann das Posting publiziert wurde)
- CATEGORY (Kategorie, der das Posting zugeordnet wurde)
- TITLE (Haupttitel des Postings)
- BODY (Hauptinhalt des Postings)
- TRACKBACK (Links von anderen Sites auf das Blog)
- COMMENTS (Kommentare, die von Usern hinzugefügt wurden)
- PERMALINK (die URL zum einzelnen Artikel)
- FOOTER (in der Regel befindet sich der Footer eines Blogs am Ende eines Postings und zeigt das Datum, die Zeit, den Autor und die Kategorie an sowie Statistiken wie Anzahl der Klicks, Kommentare und Trackbacks)
Im Vergleich zu gewöhnlichen Websites haben Blogs eine besondere Eigenschaft. Die Technologie RSS (Really Simple Syndication), die in vielen Blogs Anwendung findet, ist ein besonderes Feature. Denn mit Hilfe eines sogenannten Readers ist es möglich, aus einem Blog standardisierte Informationen abzurufen.
Entitäten in Webforen
Geht man von dem Modell der Nachrichtenübertragung aus, fallen wichtige Entitäten ins Auge: Eine davon ist der „Sender“ der Nachricht . Eine weitere Entität ist logischerweise die „Nachricht“ selbst, da sie die Voraussetzung ist, denn ohne eine Nachricht gibt es nichts zu senden, zu übertragen und zu empfangen. In einem Webforum lassen sich weitere wesentliche und wichtige Entitäten beobachten:
Entität Autor
Der Autor eines Forums ist der wesentliche Bestandteil eines Forums (Grimm, 2012, 11). Er schreibt Beiträge, die ein Webforum benötigt, um in der Community als anerkanntes Mitglied wahrgenommen zu werden (vgl. ebd.). Grimm (ebd.) unterscheidet die Autoren der Webforen nach „Heavy User“ und „Opinion Leader“. Einige Autoren gelten innerhalb einiger Foren als sog. „fortgeschrittene Benutzer“ und werden oftmals auch dementsprechend im Webforum gekennzeichnet (s. Abbildung rechts).
„Autoren mit guten Fachkenntnissen, sehr guten Beiträgen und hoher Anerkennung innerhalb einer Community werden auch als ‚Opinion Leader‘ bezeichnet und besitzen somit einen maßgeblichen Einfluss auf die Meinungsbildung in Foren“ (Grimm, 2012, 11).
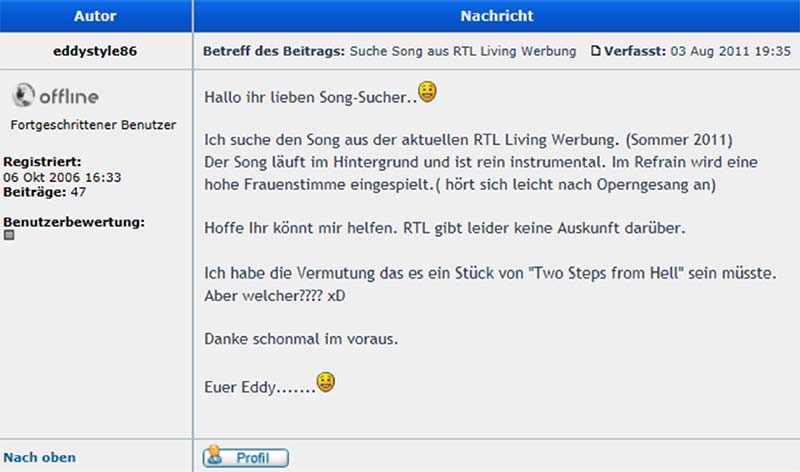
Beispiel für ein Posting eines Autoren (hier: „eddystyle86“), gekennzeichnet als „Fortgeschrittener Benutzer“ aus forum.multidat.de/viewtopic.php?f=25&t=3560
Entität Posting
„Ein Beitrag bzw. Posting ist die kleinste hierarchische Einheit innerhalb der systematischen Struktur eines Forums“ (Grimm, 2012, 10) und wird von einem Mitglied und in wenigen Fällen von einem Gast verfasst.
Entität Thread
Ein Beitrag bzw. Posting besteht aus einem sog. „Eintragstext“ (Diekmanns-henke, 2000, 142), auch Thread genannt (Grimm, 2012, 11). „Dieses englische Wort, das etymologisch mit dem deutschen Wort ‚Draht‘ verwandt ist, lässt sich heute ins Deutsche je nach Kontext mit Faden, Kette, Garn oder Gewinde übersetzen“ (Münz, 2007). Der „Eröffnungsbeitrag mit alle [sic] seinen darauf folgenden Beiträgen wird als Thread bezeichnet und kann sinngemäß als Diskussionsfaden übersetzt werden“ (Zaefferer, 2011, 13). „Ein Thread setzt sich somit aus mindestens zwei Beiträgen von unterschiedlichen Autoren zusammen“ (Grimm, 2012, 11). Folglich wird unter einem Thread sowohl das Eröffnungsposting als auch der gesamte Diskussionsfaden verstanden.
Entität Reply
Ein Reply, also eine Antwort, bezieht sich auf den Thread. Nutzer von Foren haben die Möglichkeit, auf Threads zu antworten, woraus schließlich eine Diskussion entsteht: „Durch das Antworten auf eine Frage kann eine Diskussion entstehen, in dem [sic] ein oder mehrere Benutzer auf die Frage antworten und gleichzeitig andere Beiträge kommentieren“ (Zaefferer, 2011, 19).
Entität Mitglieder
Ein Webforum hat in der Regel Mitglieder (vgl. Döring, 2003, 62-73). Im Grunde hängen der Erfolg und die Popularität eines Forums letztlich von der Aktivität sowie der Menge der Mitglieder ab. Denn die „Charakteristika des Mediums“ selbst, in der eine Nachricht veröffentlicht wird, spielen eine wesentliche Rolle für den Erfolg, die Verbreitung und Wichtigkeit oder Relevanz einer Nachricht selbst (vgl. Lasswell, 1948; vgl. Stock & Stock, 2008, 141ff).
Die Mitgliederzahl ist daher ein wichtiges Indiz für die Popularität einer Website. Die Mitglieder in Foren können je nach Webforum eine Million übersteigen und bilden eine hohe Rezipienten-Gruppe (Grimm, 2012, 34). Die Anzahl der Mitglieder sowie die Geschwindigkeit der Antworten (durchschnittliche Antwortzeit) sind ein Indiz für die Popularität eines Webforums (vgl. Grimm, 2012). Somit ergeben sich zwei weitere, wichtige indirekte Entitäten in einem Webforum:
Entität „Durchschnittliche Antwortzeit“
Die Zeit, die in einem bestimmten Forum durchschnittlich benötigt wird, bis ein Mitglied auf ein Posting eines anderen Mitglieds reagiert.
Entität „Anzahl Mitglieder“
Die Anzahl der registrierten Mitglieder in einem bestimmten Forum – meist mit einem Loginnamen aus einem Pseudonym und einem individuell gewählten Passwort.
Fazit
Durch diese Beobachtungen wird nun deutlich, welche wichtige Rolle Entitäten spielen. Es wird auch klar, dass Entitäten bereits Opinion Leader identifizieren und die Wichtigkeit bzw. den Einfluss einer Quelle automatisch bestimmen können. Hat ein Tool solche Entitäten in seiner Datenbank gespeichert, sind im Grunde der Marktforschung und -beobachtung keine Grenzen gesetzt. Es lassen sich zum Beispiel mit nur einigen Klicks Trends erkennen, wichtige Themen finden und Opinion Leader identifizieren.
Würde man beispielsweise wissen wollen, welche 10 Telekommunikationsthemen in den letzten Wochen für die meiste Diskussion innerhalb der deutschen Bevölkerung sorgten, wird folgende Abfrage an die Datenbank notwendig: „Zeige mir die Threads von Telekommunikationsforen, die in den letzten 14 Tagen kreiert worden sind, mindestens 400 Posts von mindestens 300 verschiedenen Autoren enthalten, und in der die durchschnittliche Antwortzeit bei weniger als 20 Minuten liegt“.
Eine solche Abfrage würde die Arbeit von 3 Monaten eines menschlichen Researchers auf einige Minuten beschränken. Voraussetzung ist allerdings, dass es tatsächlich eine Datenbank gibt, die unter anderem die Entitäten „Autor“, und „Erstellungsdatum“ sortiert vorliegen hat. Allgemeine Suchmaschinen wie Google und Bing, lassen solche Abfragen nicht zu. Marktforscher und Marketeers müssen also auf professionelle Social Media Monitoring Tools mit solchen Analytics-Funktionen zurückgreifen. Zumindest jedoch wird aufgrund der Erkenntnis deutlich, wie wichtig die Frage nach gut sortierten Entitäten ist.

Dr. William Sen
Dr. William Sen ist u. a. Gründer des ersten staatlich zertifizierten Lehrgangs zum Social Media Manager (TH Köln) sowie Chefredakteur des ersten Social Media Magazins in Deutschland.
Als Lehrbeauftragter lehrte er u. a. an der TH Köln in den Bereichen Social Media Management, eEntrepreneurship, Digital Publishing, Communication Controlling und strategisches Marketing. Dr. William Sen lebt und arbeitet in San Diego, Kalifornien.
digitalwelt-Kolumnist für strategisches Social Media Management
![]()
Quellen
- Chen, P. P.-S. (1976): The Entity-Relationship Model – Toward a Unified View of Data. Massachusetts Institute of Technology, 9-36, csc.lsu.edu/news/erd.pdf
- Diekmannshenke, H. (2000): Die Spur des Internetflaneurs – Elektronische Gästebücher als neue Kommunikationsform. In: Thimm, C. (Hrsg.) (1999): Soziales im Netz – Sprache, Beziehungen und Kommunikationskultur im Internet. 1. Aufl., VS Verlag für Sozialwissenschaften, Wiesbaden, 131ff.
- Döring, N. (2003): Sozialpsychologie des Internet – Die Bedeutung des Internet für Kommunikationsprozesse, Identitäten, soziale Beziehungen und Gruppen. Band 2, Hogrefe Verlag, Göttingen.
- Gebracht, C. (2010): Webmonitoring – Internetinhalte erfassen und gezielt nutzen. In: Bär, M.; Borcherding, J.; Keller, B. (2010): Fundraising im Non-Profit-Sektor – Marktbearbeitung von Ansprache bis Zuwendung. Verlag Dr. Th. Gabler, Wiesbaden.
- Grimm, D. (2012): Konzept zur Relevanzbestimmung von Internetforen und deren Beiträge am Beispiel der Automotive Industrie. Forschungspapiere Institut für e-Management Nr. 43, Social Media Verlag, Köln.
- Kamleitner, M. (2012): Facebook-Programmierung – Entwicklung von Social Apps & Websites. Galileo Press, Bonn.
- Lasswell, H. D. (1948): The Structure and Function of Communication in Society. In: Bryston, L. (Hrsg.): The Communication of Ideas. Harper & Brothers, 37-51.
- Lippmann, B.; Leide, S. (Hrsg.) (2004): Das Orwell’sche Jahrhundert? Colloquium zum 100. Geburtstag von George Orwell. Ludwigsfelder Verlagshaus, Berlin.
- Maisch, B. (2011): Vorgestellt: NodeXL. Social Media Magazin, 2011(1), 30-31.
- Michelis, D. (2010): Die Sprache der Neuen Medien (Lev Manochiv). In: Michelis, D.; Schildhauer, T. (Hrsg.) (2010): Social Media Handbuch – Theorien, Methoden, Modelle. Nomos Verlag, Baden-Baden, 42-52.
- Münz, S. (2007): Foren und Boards. Selfthtml.org, aktuell.de.selfhtml.org/artikel/gedanken/foren-boards.
- Orwell, G. (1981): 1984. New American Library, New York.
- Manovich, L. (2001): The Language of New Media. Massachusetts Institute of Technology, Massachusetts, USA, manovich.net/LNM/Manovich.pdf
- Nisbet, R.; Elder, J.; Fletcher, E. J.; Miner, G. (2009): Handbook of Statistical Analysis and Data Mining Applications. Academic Press, London, UK.
- Paquet, S. (2002): Personal Knowledge Publishing and its Uses in Research. Seb’s Open Research, Université de Montréal, radio-weblogs.com/0110772/stories/2002/10/03/personalKnowledgePublishingAndItsUsesInResearch.html.
- Sen, W. (2011): Die Zauberformel von Facebook und Twitter – Was Bill Gates vor allen anderen wusste … Social Media Magazin 2011(2), 56-63.
- Stock, W. G.; Stock, M. (2008): Wissensrepräsentation – Informationen auswerten und bereitstellen. Oldenbourg Verlag, München.
- Twitter Developers (o.D.): Streaming API Methods. dev.twitter.com/docs/streaming-api/methods#count
- Vogt, C. (2004): Informatik – Eine Einführung in Theorie und Praxis. Spektrum Akademischer Verlag, München.
- Zaefferer, A. (2011): Social Media Research – Social Media Monitoring in Internet-Foren. Social Media Verlag, Köln.



