




von Dr. William Sen
digitalwelt-Kolumnist für strategisches Social Media Management
Unternehmen haben aufgrund des unentwegt steigenden Wettbewerbs ihre Produktzyklen immer weiter verkürzt. Als Gegenreaktion ist der Konsument vom Angebot dazu erzogen worden, seine Nachfrage immer wieder zu überdenken und zu ändern. Wer heute seine Bank mehrmals innerhalb kurzer Zeit wechselt bzw. auf einen neuen Handytarif oder eine neue TV-Marke umsteigt, gilt längst nicht mehr als ein schwieriger Kunde, sondern als ein Konsument der modernen Zeit. Dadurch verlieren aber auch klassische Marktdaten schneller an Bedeutung. Die Unternehmen sind gezwungen, sich pausenlos und möglichst zügig das aktuellste Wissen über ihren Markt anzueignen. Tun sie das nicht, führen sie womöglich Produkte ein, deren Nachfrage längst erloschen ist. Vor allem traditionelle Unternehmen mit geringen Reaktionszeiten stehen heute vor einem großen Problem. Durch diese Entwicklung erlangt das Social Media Monitoring, neben klassischen Umfragen und gekauften Daten die dritte Säule der Marktforschung, immer mehr an Bedeutung. Viele Unternehmen haben sich der neuen Herausforderung der Social-Media-Marktforschung gestellt: dem richtigen Umgang mit einer bislang nicht vorstellbaren Menge von Daten, Wissen und Meinungen aus dem Web.

Sammelnde Datenbanken
Marktforschung ohne Datenbanken ist heutzutage unvorstellbar. Wer Umfragen startet, stellt seine Daten nicht mehr in Excel oder lokalen Datenträgern zusammen. Denn eine Datenbank muss heute weitaus mehr leisten. Je nach Menge der Daten ändern sich technische und auch konzeptionelle Strukturen in einer Datenbank. Zudem ist sie immer zweckgebunden und abhängig von den Anforderungen ihres Einsatzgebiets. Die Mehrzahl der Nutzer kennt Datenbanken aus Web-Applikationen, wie bei der Installation des eigenen Blogs mit WordPress. Vor allem bei solch datenbankgestützter Software sind die Anforderungen an die Datenbank eher gering. Ein durchschnittliches CMS enthält in seiner Basis-Installation eine recht überschaubare Menge an Tabellen, die unter 50.000 Datensätzen liegen können. Füllt sich das CMS später mit Text- bzw. Webinhalten, werden sie lediglich um die jeweiligen Inhalte größer. Dabei ist die Steigerung der Größe der Datenbank linear und nachvollziehbar. Kurzum: Immer wenn ein Inhalt dazu kommt, wird er hinten drangehängt – die Datenbank wächst verhältnismäßig. Derartige Systeme, wie auch CRM oder Verzeichnisse, können anfangs durchaus noch relativ gut mit freien Open-Source-Datenbanken verwaltet werden.Social Media Data Warehouse
 Linear wachsende Datentabellen bleiben in ihrer Struktur konsistent.
In der einfachen Betrachtungsweise ist eine Datenbank eine Fülle von Informationen, denn Größe allein macht noch keine Komplexität aus. Lediglich die Hardware ist zu erweitern. Sind die Daten irgendwann zu groß, können zum Beispiel neue Festplatten an die Server angeschlossen werden.
In einer erweiterten Betrachtungsweise nützt jedoch diese sogenannte „stille Datenbank“ dem Nutzer wenig, wenn er sich aus den bereitliegenden Informationen nicht seinem Bedarf entsprechend bedienen kann. In der Amateurliga stehen Daten wie Adressen und Verzeichnisse in der Datenbank zur Abfrage bereit, die alphabetisch oder nummerisch sein können. Der Abruf solcher Daten, meist unabhängig von der Größe, stellt weder den Abfragenden noch die Datenbank vor allzu große Schwierigkeiten. Wie auch in analogen Akten- oder Bibliotheksverzeichnissen kann eine Maschine relativ zügig die gewünschte Information ausfindig machen. So sind auch die Verwaltung und der Abruf von Personendaten von über 80 Millionen deutschen Bundesbürgern, trotz der zunächst enorm erscheinenden Datenbankmenge, im Grunde die einfachste Disziplin der Informationsgewinnung. Die Maschine muss lediglich aus den alphabetisch oder nummerisch sortierten Daten die gesuchte Information heraussuchen und auf dem Bildschirm ausgeben.
Das Problem jedoch ist nicht die Bereitstellung von Datenmengen oder deren Wachstum. Im Grunde ist jede Datenbank in der Lage, eine sehr große Menge von Informationen zu speichern. Doch das Sammeln von Daten macht noch lange kein Wissen aus. Denn nicht die Menge oder Größe ist ausschlaggebend, sondern die Gewinnung von handlungsrelevantem Wissen für das Unternehmen daraus.
Linear wachsende Datentabellen bleiben in ihrer Struktur konsistent.
In der einfachen Betrachtungsweise ist eine Datenbank eine Fülle von Informationen, denn Größe allein macht noch keine Komplexität aus. Lediglich die Hardware ist zu erweitern. Sind die Daten irgendwann zu groß, können zum Beispiel neue Festplatten an die Server angeschlossen werden.
In einer erweiterten Betrachtungsweise nützt jedoch diese sogenannte „stille Datenbank“ dem Nutzer wenig, wenn er sich aus den bereitliegenden Informationen nicht seinem Bedarf entsprechend bedienen kann. In der Amateurliga stehen Daten wie Adressen und Verzeichnisse in der Datenbank zur Abfrage bereit, die alphabetisch oder nummerisch sein können. Der Abruf solcher Daten, meist unabhängig von der Größe, stellt weder den Abfragenden noch die Datenbank vor allzu große Schwierigkeiten. Wie auch in analogen Akten- oder Bibliotheksverzeichnissen kann eine Maschine relativ zügig die gewünschte Information ausfindig machen. So sind auch die Verwaltung und der Abruf von Personendaten von über 80 Millionen deutschen Bundesbürgern, trotz der zunächst enorm erscheinenden Datenbankmenge, im Grunde die einfachste Disziplin der Informationsgewinnung. Die Maschine muss lediglich aus den alphabetisch oder nummerisch sortierten Daten die gesuchte Information heraussuchen und auf dem Bildschirm ausgeben.
Das Problem jedoch ist nicht die Bereitstellung von Datenmengen oder deren Wachstum. Im Grunde ist jede Datenbank in der Lage, eine sehr große Menge von Informationen zu speichern. Doch das Sammeln von Daten macht noch lange kein Wissen aus. Denn nicht die Menge oder Größe ist ausschlaggebend, sondern die Gewinnung von handlungsrelevantem Wissen für das Unternehmen daraus.
Rechnende Datenbanken in der Marktforschung
 Bei Datenmengen aus der Marktforschung geht es in der Königsliga darum, sie untereinander zu verknüpfen.
Der tatsächliche Flaschenhals liegt somit in der Bearbeitung von Daten. Im Data Mining sind der aktive Umgang sowie die Berechnungen mit den vorliegenden Informationen ausschlaggebend. Hier fängt nun das eigentliche Problem an, wenn der Forscher mit einer zu großen Menge an Daten zu tun hat.
Was sich zunächst als die Hauptaufgabe eines Datenbanksystems (DBMS) anhört, zeigt sich bei einer sehr großen Menge an Daten als problematisch. Die Treffermengen können bei einer einfachen Frage ins Unermessliche steigen, so dass der Suchende mit der überwältigenden Menge an Ergebnissen wenig anfangen kann. Sind die Abfragen zu komplex, kommt die Maschine bei Big Data ins Schleudern. Dennoch werden bei sehr großen Mengen an Daten intelligentere Suchanfragen notwendig, die einerseits sehr komplex und andererseits hoch mathematisch sein müssen. In dieser Stufe werden Abfragesprachen eingesetzt, die die Expertise von Information Professionals benötigen. Von einem Produktverantwortlichen beispielsweise, der zu seiner Frage möglichst präzise Antworten erhalten möchte, kann nicht erwartet werden, dass er derartige Abfragealgorithmen beherrscht. Um den Suchenden vor einer komplizierten Abfrage zu bewahren, müssen Abfragen zum Abruf zur Verfügung gestellt werden. Dann braucht der Nutzer des Systems nur noch die komplexe Suchanfrage per Knopfdruck zu starten.
In einer weiteren Stufe sucht der Researcher auf seine individuelle betriebswirtschaftliche Frage nach spezifischen Antworten in einer großen Datenmenge. Derartige Tools und Abfragen sind unter anderem aus Management Information Systemen (MIS), Controlling Dashboards sowie anderen Executive und entscheidungsunterstützenden Systemen bekannt und finden täglich in größeren Konzernen ihren Einsatz. Produktverantwortliche, Marketeers, Marktforscher und Entscheider aus vielen verschiedenen Bereichen des Unternehmens können innerhalb weniger Sekunden in ihrem Dashboard Kennzahlen in Form von KPIs in vielen verschiedenen Varianten abrufen. Neben den üblichen Darstellungsformen wie Kuchengrafiken, Trendanalysen, Ampelsystemen und Speedometern bieten diese Systeme auch individuell gewünschte Darstellungsformen.
Bei Datenmengen aus der Marktforschung geht es in der Königsliga darum, sie untereinander zu verknüpfen.
Der tatsächliche Flaschenhals liegt somit in der Bearbeitung von Daten. Im Data Mining sind der aktive Umgang sowie die Berechnungen mit den vorliegenden Informationen ausschlaggebend. Hier fängt nun das eigentliche Problem an, wenn der Forscher mit einer zu großen Menge an Daten zu tun hat.
Was sich zunächst als die Hauptaufgabe eines Datenbanksystems (DBMS) anhört, zeigt sich bei einer sehr großen Menge an Daten als problematisch. Die Treffermengen können bei einer einfachen Frage ins Unermessliche steigen, so dass der Suchende mit der überwältigenden Menge an Ergebnissen wenig anfangen kann. Sind die Abfragen zu komplex, kommt die Maschine bei Big Data ins Schleudern. Dennoch werden bei sehr großen Mengen an Daten intelligentere Suchanfragen notwendig, die einerseits sehr komplex und andererseits hoch mathematisch sein müssen. In dieser Stufe werden Abfragesprachen eingesetzt, die die Expertise von Information Professionals benötigen. Von einem Produktverantwortlichen beispielsweise, der zu seiner Frage möglichst präzise Antworten erhalten möchte, kann nicht erwartet werden, dass er derartige Abfragealgorithmen beherrscht. Um den Suchenden vor einer komplizierten Abfrage zu bewahren, müssen Abfragen zum Abruf zur Verfügung gestellt werden. Dann braucht der Nutzer des Systems nur noch die komplexe Suchanfrage per Knopfdruck zu starten.
In einer weiteren Stufe sucht der Researcher auf seine individuelle betriebswirtschaftliche Frage nach spezifischen Antworten in einer großen Datenmenge. Derartige Tools und Abfragen sind unter anderem aus Management Information Systemen (MIS), Controlling Dashboards sowie anderen Executive und entscheidungsunterstützenden Systemen bekannt und finden täglich in größeren Konzernen ihren Einsatz. Produktverantwortliche, Marketeers, Marktforscher und Entscheider aus vielen verschiedenen Bereichen des Unternehmens können innerhalb weniger Sekunden in ihrem Dashboard Kennzahlen in Form von KPIs in vielen verschiedenen Varianten abrufen. Neben den üblichen Darstellungsformen wie Kuchengrafiken, Trendanalysen, Ampelsystemen und Speedometern bieten diese Systeme auch individuell gewünschte Darstellungsformen.
Social Media Inhalte
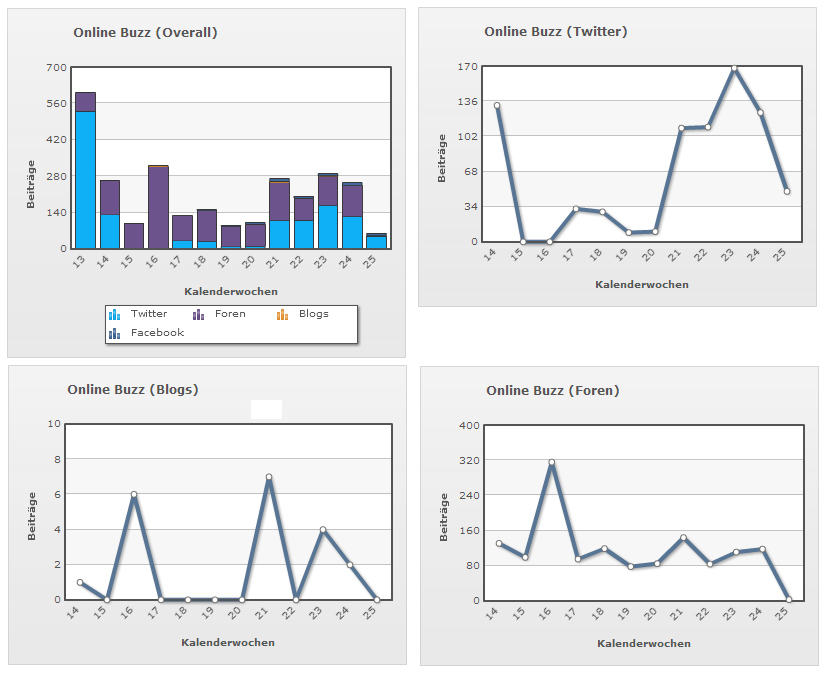 Derartige Charts, die der Entscheider in seinem Cockpit wiederfindet, sind auf komplexe Abfragen im Hintergrund zurückzuführen.
Diese eher informatik- oder mathematik-getriebene Ebene läuft im Hintergrund ab und aggregiert verschiedene dem Unternehmen vorliegende Daten zu einer Form, die der Mensch verstehen kann. Wie nun tatsächlich die Abfrage im Hintergrund stattfindet, ist oft das Hoheitsgebiet des Controllers – vor allem dann, wenn es beispielsweise um Daten aus dem Finanzcontrolling geht.
Während vor allem im Finanzwesen Berechnungen eine lange Lernperiode hinter sich haben und außerdem etablierte Finanzkennzahlen zum Einsatz kommen, ist die Bearbeitung von Social-Media-Daten derweil noch ein neues Gebiet. Und gleichzeitig mit der Beschäftigung der Experten mit klaren Kennzahlen und Berechnungsgrundlagen von Social Media Content kommt noch eine weitere Herausforderung hinzu: Die Daten aus dem Social Web haben überdimensionale Größen. Somit erlangt die Frage an Bedeutung, wie Abfragen an eine solch riesige Datenbank gestellt werden können. Während im Vergleich zum Finanzwesen im Unternehmen die Kennzahlen direkt aus dem Controlling stammen, stellt sich bei Social Media noch eine weitere wichtige Frage: „Woher sollen diese großen Mengen von Social-Media-Inhalten beschafft werden?“
Derartige Charts, die der Entscheider in seinem Cockpit wiederfindet, sind auf komplexe Abfragen im Hintergrund zurückzuführen.
Diese eher informatik- oder mathematik-getriebene Ebene läuft im Hintergrund ab und aggregiert verschiedene dem Unternehmen vorliegende Daten zu einer Form, die der Mensch verstehen kann. Wie nun tatsächlich die Abfrage im Hintergrund stattfindet, ist oft das Hoheitsgebiet des Controllers – vor allem dann, wenn es beispielsweise um Daten aus dem Finanzcontrolling geht.
Während vor allem im Finanzwesen Berechnungen eine lange Lernperiode hinter sich haben und außerdem etablierte Finanzkennzahlen zum Einsatz kommen, ist die Bearbeitung von Social-Media-Daten derweil noch ein neues Gebiet. Und gleichzeitig mit der Beschäftigung der Experten mit klaren Kennzahlen und Berechnungsgrundlagen von Social Media Content kommt noch eine weitere Herausforderung hinzu: Die Daten aus dem Social Web haben überdimensionale Größen. Somit erlangt die Frage an Bedeutung, wie Abfragen an eine solch riesige Datenbank gestellt werden können. Während im Vergleich zum Finanzwesen im Unternehmen die Kennzahlen direkt aus dem Controlling stammen, stellt sich bei Social Media noch eine weitere wichtige Frage: „Woher sollen diese großen Mengen von Social-Media-Inhalten beschafft werden?“
Social-Media-Datenbanken
 Während beim Finanzcontrolling die Abfragen, so komplex sie auch sein mögen, auf eine gewissermaßen nachvollziehbare Menge an Daten zurückgreifen, sind die Dimensionen in Social Media mit keiner anderen Datenbasis vergleichbar.
Es spielt eine große Rolle, ob eine komplexe Abfrage an eine Datenbank mit 2 Millionen oder 10 Milliarden Datensätzen gestellt wird. Erfahrungsgemäß kommen ab einer bestimmten Größe Datenbanken ins Schwanken, wenn sie logarithmierte Abfragen bearbeiten sollen. Vor allem Systemabstürze, Fehler oder schlicht eine zu lange Zeit zum Berechnen der Ergebnisse sind die ersten bekannten Symptome, die sich oftmals auch bei einfacheren Systemen sowie Open-Source-Datenbanken zeigen. Greift man auf kommerzielle Datenbanken zu, beispielsweise Oracle, Microsoft SQL Server oder dBASE, zeigt sich, dass hier bereits andere Mechanismen zur Bewältigung von Big Data vorgesehen sind. Von den Datenbankherstellern sind zum Beispiel durchaus auch selbst patentierte Komprimierungsmethoden und -konzepte im System vorhanden. Trotz der Vielfalt der meist fortschrittlichen DBMS stoßen jedoch auch diese irgendwann an ihre Grenzen. Daher werden Konzepte und Methoden notwendig, die bereits bei der Erfassung der Daten die große Menge berücksichtigen müssen. Das Motto „erst sammeln, dann bearbeiten“ greift also an dieser Stelle nicht mehr.
Während beim Finanzcontrolling die Abfragen, so komplex sie auch sein mögen, auf eine gewissermaßen nachvollziehbare Menge an Daten zurückgreifen, sind die Dimensionen in Social Media mit keiner anderen Datenbasis vergleichbar.
Es spielt eine große Rolle, ob eine komplexe Abfrage an eine Datenbank mit 2 Millionen oder 10 Milliarden Datensätzen gestellt wird. Erfahrungsgemäß kommen ab einer bestimmten Größe Datenbanken ins Schwanken, wenn sie logarithmierte Abfragen bearbeiten sollen. Vor allem Systemabstürze, Fehler oder schlicht eine zu lange Zeit zum Berechnen der Ergebnisse sind die ersten bekannten Symptome, die sich oftmals auch bei einfacheren Systemen sowie Open-Source-Datenbanken zeigen. Greift man auf kommerzielle Datenbanken zu, beispielsweise Oracle, Microsoft SQL Server oder dBASE, zeigt sich, dass hier bereits andere Mechanismen zur Bewältigung von Big Data vorgesehen sind. Von den Datenbankherstellern sind zum Beispiel durchaus auch selbst patentierte Komprimierungsmethoden und -konzepte im System vorhanden. Trotz der Vielfalt der meist fortschrittlichen DBMS stoßen jedoch auch diese irgendwann an ihre Grenzen. Daher werden Konzepte und Methoden notwendig, die bereits bei der Erfassung der Daten die große Menge berücksichtigen müssen. Das Motto „erst sammeln, dann bearbeiten“ greift also an dieser Stelle nicht mehr.
Spezielle Suchmaschinen

Prof. Lev Manovich der University of California, San Diego ist einer der führenden Data-Mining-Experten im Umgang mit Social Media
Die Erfassung
Insgesamt gibt es in der Aufbereitung von Social-Media-Daten bzw. Big Data verschiedene Betrachtungsweisen. In der Datenbeschaffung spielen zwei Konzepte im Sammeln von Social-Media-Inhalten eine wichtige Rolle: die Auswahl (Focused Crawling) und die Struktur (Entity Crawling) der Daten.Focused Crawling: Die richtigen Daten auswählen
Die Methode des Focused Crawlings geht darauf zurück, dass nicht alle Daten des Webs erfasst werden können bzw. sollen. Bei einem Focused Crawler handelt es sich um eine spezielle Funktion einer Suchmaschine. Für allgemeine Zwecke stehen derartige Suchmaschinen in der Regel nicht zur Verfügung. Der Normalverbraucher hat somit selten Zugriff auf sie. „Allgemeine Suchmaschinen ersuchen, potenziell alle im Web vorhandenen Dokumente zu erschließen“ (Lewandowski, 2009a, 54). Zudem richten sich derartige Suchmaschinen am Durchschnittsnutzer aus. Sie müssen „ein möglichst breites Spektrum möglicher Nutzerinteressen berücksichtigen“ (Riemer & Brüggemann, 2009, 148). Spezielle Suchmaschinen sind dagegen für bestimmte Bereiche des Webs zuständig (Lewandowski, 2009a, 57). Dies zeigt sich auch im Verhalten des Crawlers, also der Maschine, die das Web durchsucht und in die Datenbank einspeist: Sie ist eine Technologie, die zur Erfassung oder Bereitstellung von Informationen für bestimmte Fachbereiche konzipiert wurde. Während sich ein Unternehmen beispielsweise für Telekommunikationsforen und Foren aus benachbarten Bereichen interessiert, beschäftigt sich ein Unternehmen aus der Baubranche vorrangig mit Bauforen und -blogs.Social Media Crawler
„Zum Suchen von Dokumenten wird ein allgemeiner Crawler eingesetzt, der Webseiten aufspürt, um große Datenspeicher aufzubauen.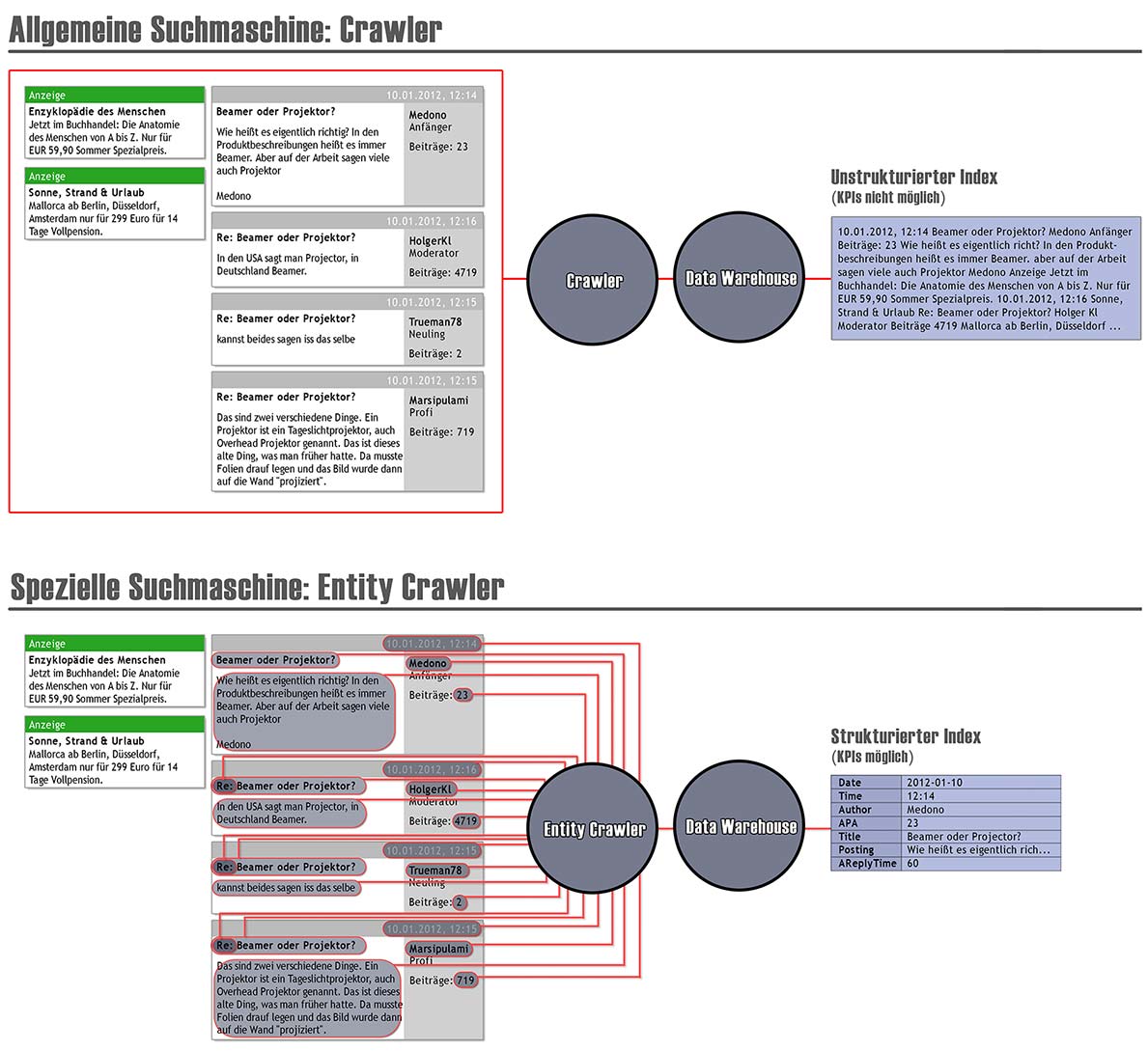 Focused Crawler gehen dagegen gezielter vor: Maßgeblich ist nicht, enorme Datenmengen zu durchsuchen, zu speichern und zu indexieren, sondern nur bestimmte, thematisch relevante Segmente des World Wide Web. Der Focused Crawler muss einen möglichst optimalen Weg durch das Web finden, um Knowledge Discovery zu betreiben“ (Kwiatkowski & Höhfeld, 2007, 69).
Für die Zusammenstellung kommt noch eine „White List“ zum Einsatz, die zu indexierende Webquellen zu einem bestimmten Themenbereich bereithält (Lewandowski, 2009a, 57). Das Ziel liegt also nicht darin, sporadisch auftauchende Webadressen zu finden. Es dürfen in einem bestimmen Bereich oder einer speziellen Branche nur die relevanten Quellen indexiert werden.
Focused Crawler gehen dagegen gezielter vor: Maßgeblich ist nicht, enorme Datenmengen zu durchsuchen, zu speichern und zu indexieren, sondern nur bestimmte, thematisch relevante Segmente des World Wide Web. Der Focused Crawler muss einen möglichst optimalen Weg durch das Web finden, um Knowledge Discovery zu betreiben“ (Kwiatkowski & Höhfeld, 2007, 69).
Für die Zusammenstellung kommt noch eine „White List“ zum Einsatz, die zu indexierende Webquellen zu einem bestimmten Themenbereich bereithält (Lewandowski, 2009a, 57). Das Ziel liegt also nicht darin, sporadisch auftauchende Webadressen zu finden. Es dürfen in einem bestimmen Bereich oder einer speziellen Branche nur die relevanten Quellen indexiert werden.
Entity Crawling: Die Spreu vom Weizen trennen
Die Spezialsuchmaschinen, die Social-Media-Inhalte selbst indexieren, haben noch eine weitere wichtige Eigenschaft: die strukturelle Erfassung der Daten. Gegenüber anderen Suchtechnologien setzen sie sich nicht zum Ziel, den Fokus auf die Erfassung von massenhaften Daten zu legen. In einem Volltextindex, wie er in allgemeinen Suchmaschinen vorkommt, fehlen vor allem klare Entitäten – diese sind zum Beispiel „Autorenname“, „Datum“, „Reply“, „Länge des Threads“, „durchschnittliche Antwortzeiten“, „Anzahl der Postings der jeweiligen Autoren“, „Anzahl der Mitglieder des Forums“, „Registrierungsdatum des Autors“ und viele mehr. Diese Messgrößen haben in Social Media Notwendigkeit, wenn Marktforscher sie miteinander sowohl mathematisch als auch empirisch verknüpfen wollen, um wichtige Erkenntnisse aus den Daten abzuleiten. Erst derartige Messwerte können beispielsweise KPIs zu „Reichweiten“, „Wichtigkeit“, „Impact“ und vielen mehr berechnen lassen.Social Media Mining
Der Data-Mining-Experte Manovich der University of California geht davon aus, dass alle im Web vorliegenden Objekte, auch wenn sie auf den ersten Blick keine Struktur zu besitzen scheinen, einer mathematischen Formel zugeordnet werden können.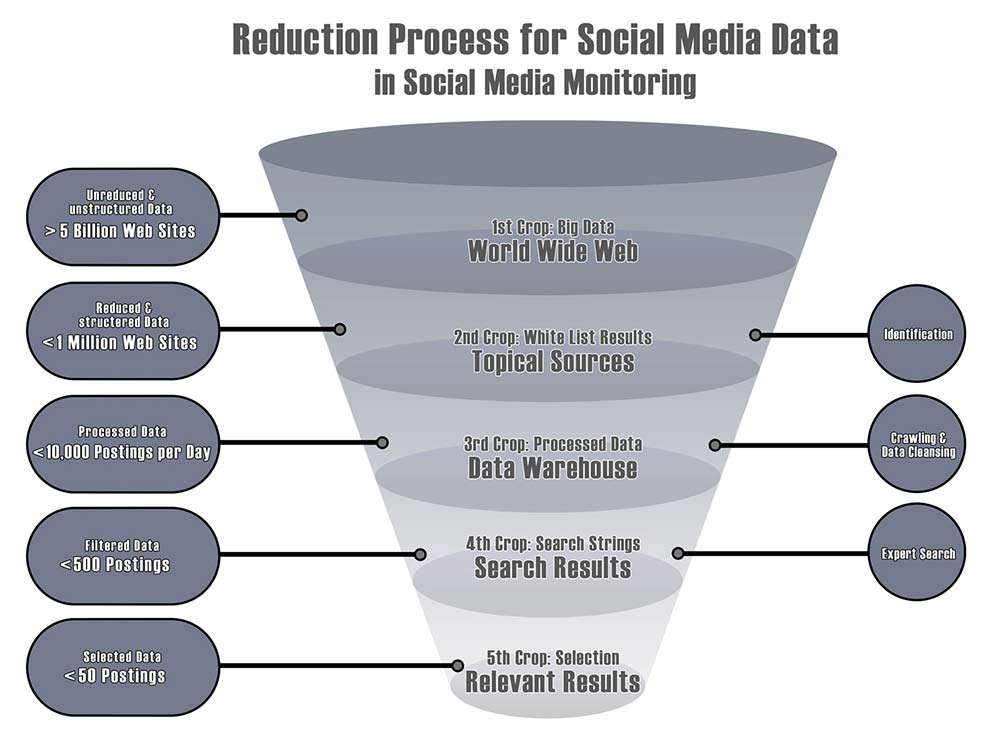 Des Weiteren sieht Prof. Manovich die Möglichkeit der Automatisierung der Daten aus dem Web (Manovich, 2001, 49). Daraus wird deutlich, dass die strukturelle Erfassung der Daten im Social Web notwendig ist.
Prof. Fank von der Technischen Hochschule Köln schlägt in seinem Konzept des Webknowledge vor, die Strukturen im Web bereits bei der Phase des Indexierens zu erkennen und erst dann in die Datenbank einzuspeisen. Die Herausforderung liegt auf der Hand: In Social Media herrschen unstrukturierte Daten und vor allem komplexe Datenstrukturen (Bucher et al., 2008, 44f).
Der Erfinder des Webs Tim Berners-Lee (2002, 25) macht darauf aufmerksam, dass das Web für Menschen gemacht worden ist, der Computer allerdings beim Erfassen von Daten Schwierigkeiten hat. Viele Quellen, seien es beispielsweise individuelle Websites oder speziell programmierte Foren, haben oft eine vom Administrator nach eigenem Ermessen erstellte Struktur. Bei einer strukturellen Erfassung geht es also darum, alle Inhalte, die im Web und somit auch in Social Media vorhanden sind, unter eine gemeinsame Struktur zu bringen. Die Struktur der Daten muss jedoch einem Zweck folgen, d. h. im Vordergrund steht das wirtschaftliche Unternehmen, das seine Fragestellung beantwortet wissen möchte. Die Aufgabe ist also, die unstrukturierten Daten im Web so kodieren zu lassen, „dass sie für Computerprogramme fassbar werden“ (Schneider, 2008, 113).
Des Weiteren sieht Prof. Manovich die Möglichkeit der Automatisierung der Daten aus dem Web (Manovich, 2001, 49). Daraus wird deutlich, dass die strukturelle Erfassung der Daten im Social Web notwendig ist.
Prof. Fank von der Technischen Hochschule Köln schlägt in seinem Konzept des Webknowledge vor, die Strukturen im Web bereits bei der Phase des Indexierens zu erkennen und erst dann in die Datenbank einzuspeisen. Die Herausforderung liegt auf der Hand: In Social Media herrschen unstrukturierte Daten und vor allem komplexe Datenstrukturen (Bucher et al., 2008, 44f).
Der Erfinder des Webs Tim Berners-Lee (2002, 25) macht darauf aufmerksam, dass das Web für Menschen gemacht worden ist, der Computer allerdings beim Erfassen von Daten Schwierigkeiten hat. Viele Quellen, seien es beispielsweise individuelle Websites oder speziell programmierte Foren, haben oft eine vom Administrator nach eigenem Ermessen erstellte Struktur. Bei einer strukturellen Erfassung geht es also darum, alle Inhalte, die im Web und somit auch in Social Media vorhanden sind, unter eine gemeinsame Struktur zu bringen. Die Struktur der Daten muss jedoch einem Zweck folgen, d. h. im Vordergrund steht das wirtschaftliche Unternehmen, das seine Fragestellung beantwortet wissen möchte. Die Aufgabe ist also, die unstrukturierten Daten im Web so kodieren zu lassen, „dass sie für Computerprogramme fassbar werden“ (Schneider, 2008, 113).
Social Media Indexer
Das Konzept ist demnach eine Maschine, die Daten aus dem Web bereits strukturiert indexiert, also nur innerhalb einer Website nach bestimmten Erkennungsmerkmalen Ausschau hält. Dadurch werden vom Crawler die Tabellen in der Datenbank bereits nach Entitäten (Autorenname, Datum etc.) sortiert abgelegt. Ein derartiger Crawler betrachtet somit die Daten aus dem Web nicht als gleichwertige Inhalte, sondern nimmt bereits beim Indexieren eine Selektion vor. Dadurch bleibt die Problematik von reinen Textinhalten erspart, die man nicht mathematisch bearbeiten kann.Focused Crawer

Erfassung des Web 2.0
Ein weiteres Konzept der Technischen Hochschulen Köln sorgt dafür, dass das gesamte Web in Schichten unterteilt wird. Entwickelt u. a. vom Informationswissenschaftler Prof. Fank, zeigt dieses Modell, dass jedes im Web vorhandene Medium technisch mit bestimmten Spezifikationen behandelt werden muss. Foren haben beispielsweise andere Eigenschaften als Blogs und sollten daher in der Identifikation, Indexierung und Analyse speziell bedient werden. Auch die konkreten Handlungsempfehlungen können je nach Medium unterschiedlich ausfallen.Die Abfrage
Das Universum ist groß. Es gesamt zu erfassen, scheint unmöglich zu sein. Durch den Fokus auf nur eine Galaxie verschwindet das Problem aber noch lange nicht. Denn auch eine Galaxie ist für einen Menschen unvorstellbar riesig. Mit Focused Crawling werden zwar die Daten in Social Media durch eine spezielle Suchmaschine erst ausgewählt und danach strukturiert abgelegt. Dennoch ist am Ende dieser Kette die Datenbank weiterhin immens groß. Das oben beschriebene Erfassungskonzept mit Focused Crawling für Social Media sorgt dafür, dass aus einer zunächst scheinbar unendlichen Menge von Daten nur die relevanten in die Datenbank eingespeist werden. Zudem liegen diese Daten wie oben beschrieben auch strukturiert vor, so dass Data Mining und auch die Erstellung von KPIs möglich sind. Eine Anwendung von mathematischen und statistischen Methoden, um darin neue Muster zu erkennen und wirtschaftliche Fragen über diese Daten zu beantworten, wird durch eine strukturierte Datenbank erst möglich.Social Media Beiträge
Es ist notwendig, sich eine Vorstellung über die Größenverhältnisse zu machen. Allein in Deutschland gibt es insgesamt 1.557 Internet-Quellen, die sich nur mit dem Thema „Telefonie“ befassen. Bereits in einem einzigen Webforum werden täglich zu einem bestimmten Thema mehr als 10.000 Beiträge publiziert (Fank & Ottawa, 2011). Drittes Beispiel: Das Automobilforum Motor-Talk hat knapp 2 Millionen Mitglieder, mehr als 700.000 einzelne Pages und mehr als 20 Millionen Beiträge. Ein Focused Crawler sammelt also eine sehr große Menge an Daten, die zudem nicht nur Foren, sondern auch Blogs, Twitter-Beiträge, Facebook sowie alle in Frage kommenden Social-Media-Kanäle beinhaltet.
Dem Erfassungskonzept folgt eine Methode, die auch die Abfrage einbeziehen muss. Das Unternehmen wünscht schließlich keine Auflistung der Ergebnisse mit überdimensionalen Trefferzahlen, da diese bereits mit Google geliefert werden kann. Ein durchschnittlicher Nutzer ist meist mit den ersten 10 Treffern in einer Suchmaschine zufrieden, wenn er die gesuchte Information findet. Aber für ein Unternehmen, das alle Beiträge über sein Produkt im Web erfassen möchte, ist diese Methode nicht zielführend. Hierbei kommen betriebswirtschaftliche Aspekte zum Tragen. Die Ansprüche im Social Media Monitoring sind daher Trendanalysen, Alerts, Buzzmonitoring, Reichweitenanalysen und -charts sowie KPIs zu verschiedenen Themen. Für derartige Abfragen müssen somit Berechnungen und Algorithmen eingesetzt werden. Die wichtige Frage für das Unternehmen ist darum: „Wie kann ich aus einer Fülle von Daten diejenigen filtern, die nur mein Unternehmen betreffen?“
Die Methode, die vor allem bei Social Media Monitoring genutzt wird, beinhaltet den Einsatz von Search Strings. Komplexe und mathematisch verknüpfte Keywords, Zeitfilter sowie Mengenangaben wie Anzahl Threads und Anzahl Replies sorgen dafür, dass am Bildschirm aus einer großen Menge von Daten lediglich die Postings mit der höchsten Reichweite und der größten Relevanz angezeigt werden. Am Ende eines Prozesses können dies zum Beispiel nur wenige Duzend Beiträge sein, die ein Produktverantwortlicher nun mit deutlich weniger Aufwand durchlesen kann.
Bereits in einem einzigen Webforum werden täglich zu einem bestimmten Thema mehr als 10.000 Beiträge publiziert (Fank & Ottawa, 2011). Drittes Beispiel: Das Automobilforum Motor-Talk hat knapp 2 Millionen Mitglieder, mehr als 700.000 einzelne Pages und mehr als 20 Millionen Beiträge. Ein Focused Crawler sammelt also eine sehr große Menge an Daten, die zudem nicht nur Foren, sondern auch Blogs, Twitter-Beiträge, Facebook sowie alle in Frage kommenden Social-Media-Kanäle beinhaltet.
Dem Erfassungskonzept folgt eine Methode, die auch die Abfrage einbeziehen muss. Das Unternehmen wünscht schließlich keine Auflistung der Ergebnisse mit überdimensionalen Trefferzahlen, da diese bereits mit Google geliefert werden kann. Ein durchschnittlicher Nutzer ist meist mit den ersten 10 Treffern in einer Suchmaschine zufrieden, wenn er die gesuchte Information findet. Aber für ein Unternehmen, das alle Beiträge über sein Produkt im Web erfassen möchte, ist diese Methode nicht zielführend. Hierbei kommen betriebswirtschaftliche Aspekte zum Tragen. Die Ansprüche im Social Media Monitoring sind daher Trendanalysen, Alerts, Buzzmonitoring, Reichweitenanalysen und -charts sowie KPIs zu verschiedenen Themen. Für derartige Abfragen müssen somit Berechnungen und Algorithmen eingesetzt werden. Die wichtige Frage für das Unternehmen ist darum: „Wie kann ich aus einer Fülle von Daten diejenigen filtern, die nur mein Unternehmen betreffen?“
Die Methode, die vor allem bei Social Media Monitoring genutzt wird, beinhaltet den Einsatz von Search Strings. Komplexe und mathematisch verknüpfte Keywords, Zeitfilter sowie Mengenangaben wie Anzahl Threads und Anzahl Replies sorgen dafür, dass am Bildschirm aus einer großen Menge von Daten lediglich die Postings mit der höchsten Reichweite und der größten Relevanz angezeigt werden. Am Ende eines Prozesses können dies zum Beispiel nur wenige Duzend Beiträge sein, die ein Produktverantwortlicher nun mit deutlich weniger Aufwand durchlesen kann.
Entity Crawling
Reduktionsprozess
Aufgrund der großen Menge an Daten muss zwangsläufig ein Reduktionsprozess stattfinden. Die Ausgangslage ist das Web, in dem mehr als 5 Milliarden Websites in verschiedenen Strukturen vorhanden sind. In der zweiten Stufe (2nd Crop) werden in einem Identifikationsprozess Quellen ausgesucht, die für das Unternehmen relevant sind. Diese Auswahl wird in einer sogenannten White List festgehalten. Eine spezielle Suchmaschine crawlt regelmäßig diese für sie vorgesehenen Quellen und legt die Ergebnisse in einer Datenbank ab. Dort werden die Daten mehrfach bearbeitet, sortiert und bereinigt, so dass sie am Ende strukturiert und abfragebereit in einem Data Warehouse vorliegen. Eine Expertensuche (4th Crop) sorgt nun dafür, dass eine komplexe Suchabfrage generiert wird, die nur solche Quellen abruft, die für ein Unternehmen von Interesse sind. Dabei kommen vor allem Zeit- und Mengeneingaben zum Einsatz. Eine solche Abfrage kann zum Beispiel so aufgebaut sein, dass sie nur Diskussionen aufzeigt, in denen mehr als 50 verschiedene Autoren aktiv waren, mehr als 200 Replies vorhanden sind, der erste Beitrag nicht länger als 4 Wochen zurückliegt, die durchschnittliche Antwortzeit unter einem Tag liegt und der Begriff „iPhone“ in Kombination mit dem Keyword „Tarif“ mindestens 10-mal gefallen ist. Derartige Abfragen sind nur speziellen Suchmaschinen vorbehalten, denen Daten aus dem Entity Crawling zugrunde liegen.Social Media Server
Die große Menge in Social Media führt dazu, dass Konzepte und Methoden in der Sammlung und im Abruf von Daten zum Einsatz kommen müssen. Eine Suchmaschine, die solche Daten erfassen und bearbeiten möchte, muss zweckgebunden sein. Zwar haben allgemeine Suchmaschinen wie Google und Bing eine enorme Anzahl an Servern und Technologien und damit eine sehr große Datenmenge. Doch ihre Aufgaben bestehen darin, dem durchschnittlichen Nutzer bei seiner alltäglichen Suche nach Informationen zu helfen und Werbeanzeigen zu verkaufen. Sie präsentieren lediglich Suchtreffer nach einer selbst bestimmten Relevanz und können für betriebswirtschaftliche Kennzahlen nicht angewendet werden. Um wirtschaftliche Fragestellungen eines Unternehmens beantworten zu können, Data Mining zu betreiben und KPIs zu berechnen, sind spezielle Suchmaschinen gefragt, die nur für diesen Zweck vorgesehen sind.Social Media Monitoring Anbieter
Vorreiter in diesem Bereich sind eigens konzipierte Tools von Social-Media-Monitoring-Anbietern. Doch aufgrund der sehr hohen Ansprüche an die Hardware und an das Wissen mit Big Data sind derartige Anbieter auf dem Markt rar. Die Eintrittsbarrieren im Markt sind sehr hoch, da neben einer massiven IT-Infrastruktur auch ein strategisches und durchdachtes Konzept notwendig wird. Das Fraunhofer Institut nannte in Deutschland nur 6 Anbieter für Social Media Monitoring Tools (wir berichteten in der Ausgabe 2011-1), obwohl auf dem Markt derzeit mehr als 170 Anbieter für Social Media Monitoring werben. Es ist davon auszugehen, dass mehr als 90% dieser Anbieter lediglich ein intellektuelles Alerting durch den Einsatz von Google & Co. anbieten, weitergehende Berechnungen entweder nicht angeboten werden oder auf andere professionelle Monitoring-Technologien zurückgegriffen werden muss. Zwar gibt es derweil auch amerikanische Unternehmen wie Radian6, doch am deutschen Markt hat die Software den entscheidenden Durchbruch noch nicht geschafft. Beispielsweise bietet Radian6 bis heute kein Webknowledge mit Focused- und Entity-Crawling an, die in Deutschland für die Erfassung von Foren unerlässlich sind. Unternehmen müssen die Ansprüche an das Social Media Monitoring und Big Data konzeptionell verstehen, um die Auswahl der eingesetzten Methoden korrekt zu hinterfragen. Sie kommen nicht darum herum, sich dieses Wissen anzueignen, wenngleich das Thema um Big Data oft sehr viel technisches Verständnis voraussetzt. Die besten Vorzeige-Dashboards und Kennzahlen helfen wenig, wenn man nicht nachvollziehen kann, nach welcher Methodik die Daten eigentlich bearbeitet worden sind. Letztlich ist nur eine gute und gesunde Datenbasis der Garant für richtige Entscheidungen im Unternehmen.Über den Autoren
Dr. William Sen gehört weltweit zu den Top 16 Experten der Welt für Big Data. Strategia Digital, einer der führenden Medienforschungsunternehmen, untersuchte in ihrer Forschung (strategiadigital.de/big-data-experten-die-sie-kennen-sollten) die Big-Data-Experten weltweit. Gemäß der Studie gibt es 42 Experten weltweit, die man kennen sollte. Keine allzu große Zahl, sagt Strategia Digital. In der privaten Wirtschaft dagegen sind es gar nur 16 Experten. Auf der Liste sind beispielsweise der Vice President von IBM sowie der LinkedIn-Forscher Patil aufgeführt, und darunter sieht man auch den Informationswissenschaftler und Autoren dieses Artikels Dr. William Sen. Warum Dr. William Sen zu einem der weltweit 16 Experten für Big Data gehört, erklärt sich wie folgt. Er hat bereits frühzeitig eine Fülle von Publikationen zum Thema Big Data veröffentlicht – bei diesen präsentiert er auch unter anderem die Ergebnisse seiner jahrelangen Forschungsarbeiten an diversen Hochschulen. Auch sein letztes wissenschaftliches Buch „Social Media Measurement“ beschäftigt sich teilweise mit Big Data. Am 25.6.2014 hielt Dr. Sen außerdem einen Vortrag zum Thema Monitoring und Big Data bei der Govermedia, u. a. gegenüber Staatsanwälten, Polizei und Soldaten. Die Govermedia wird im Auftrag des Bundesministeriums der Verteidigung durch die Bundeswehr-Akademie für Information und Kommunikation (AIK) durchgeführt.
Quellen
- Berners-Lee, T.; Hendler, J.; & Lassila, O. (2002): The Semantic Web: A New Form of Web Content that is Meaningful to Computers will Unleash a Revolution of New Possibilities. In: Scientific American Special Online Issue, 24-30, med.nyu.edu/research/pdf/mainim01-1484312.pdf (aufgerufen am 08.04.2012).
- Fank, M.; Ottawa, M (2011), Die Rolle der Marktforschung im Rahmen des Social Media Monitoring bei der Deutschen Telekom. 46. Kongress der Deutschen Marktforschung, Vortrag von Prof. Dr. Matthias Fank, FH Köln und Marco Ottawa, Telekom Deutschland GmbH, Themenschwerpunkt 3: Generation 3.0: Nie werden Konsumenten so kommunikativ sein wie morgen, 24. Mai 2011, Folie Nr. 9.
- Kwiatkowski, M.; Höhfeld, S. (2007): Thematisches Aufspüren von Web-Dokumenten – Eine kritische Betrachtung von Focused Crawling-Strategien. Information Wissenschaft und Praxis 2007(58), 69-82. Lewandowski, D. (2009a): Spezialsuchmaschinen. In: Lewandowski, D. (Hrsg.) (2009): Handbuch Internet-Suchmaschinen – Nutzerorientierung in Wissenschaft und Praxis. Akademische Verlagsgesellschaft AKA, Heidelberg, 53-69.
- Manovich, L. (2001): The Language of New Media. Massachusetts Institute of Technology, USA. manovich.net/LNM/Manovich.pdf (aufgerufen am 12.04.2012).
- Riemer, K.; Brüggemann, F. (2009): Personalisierung der Internetsuche – Lösungstechniken und Marktüberblick. In: Lewandowski, D. (Hrsg.) (2009): Handbuch Internet-Suchmaschinen – Nutzerorientierung in Wissenschaft und Praxis. Akademische Verlagsgesellschaft AKA, Heidelberg, 148-171.
- Schneider, R. (2008): Web 3.0 ante portas? Integration von Social Web und Semantic Web. In: Zerfaß, A.; Welker, M.; Schmidt, J. (Hrsg.) (2008): Kommunikation, Partizipation und Wirkungen im Social Web – Band 1: Grundlagen und Methoden: Von der Gesellschaft zum Individuum. DGOF, Neue Schriften zur Online-Forschung 2, Herbert von Halem Verlag, 112-128, Köln.
Dr. William Sen
digitalwelt-Kolumnist für strategisches Social Media Management
Dr. William Sen ist u. a. Gründer des ersten staatlich zertifizierten Lehrgangs zum Social Media Manager (TH Köln) sowie Chefredakteur des ersten Social Media Magazins in Deutschland.
Als Lehrbeauftragter lehrte er u. a. an der TH Köln in den Bereichen Social Media Management, eEntrepreneurship, Digital Publishing, Communication Controlling und strategisches Marketing. Dr. William Sen lebt und arbeitet in San Diego, Kalifornien.







