




Ein wesentlicher Teil des Social-Media-Monitoring-Prozesses ist die Erfassung von Daten. Verschiedene Ansätze zur Datengewinnung können hier aufgezählt werden.
Daten können manuell gewonnen werden (manuelle Datengewinnung). Sie können vollautomatisch gewonnen werden – meist mit dem Einsatz von Social Media Crawlern oder Social Media Monitoring Technologien (vollautomatische Datengewinnung). Oder sie können per Schnittstelle bezogen werden – hierbei kommen sogenannte Social Media APIs (Application Programming Interfaces) zum Einsatz (Datengewinnung per API).
Manuelle Datengewinnung

Die sicherlich einfachste Herangehensweise ist die manuelle Datengewinnung. Unabhängig davon, ob eine Datenbank oder lediglich eine Excel-Tabelle genutzt wird, sucht und sammelt bei dieser Methode ein Mensch die relevanten Daten und pflegt diese ein. So können Foren-, Blog- und sonstige Social-Media-Inhalte ohne die Unterstützung einer Indexierungstechnologie gesammelt werden.
Kleine Datenmengen
Vor allem bei kleineren Datenmengen in der Größenordnung bis zu rund 300 Einträgen kann diese Art der Datensammlung schnelle Ergebnisse liefern. Dies betrifft beispielsweise Presseportale, bei denen vor allem die von Nutzern generierten Kommentare erfasst werden sollen. Ist die Anzahl der Pressenachrichten gering, kann ein Researcher diese kleinen Mengen von Postings ohne Hilfsmittel erfassen.
Große Datenmengen
Bei einer größeren Datenmenge ist der Aufwand manuell nicht mehr zu bewerkstelligen. Die Indexierung großer Foren oder einer Fülle von Blogs lässt sich vor allem nicht in kurzer Zeit realisieren. Unternehmen sind jedoch fast ausschließlich an aktuellen Beiträgen interessiert.
Umfassendes Monitoring
Ein umfassendes Social Media Monitoring bietet daher immer eine automatische Datengewinnung an. Die manuelle Erfassung kann für kleinere Projekte als Zusatzoption zu dieser eingesetzt werden.
Automatische Datengewinnung im Monitoring
Bei der automatischen Indexierung kommt ein Crawler (auch Spider, Searchbot, Robot oder Bot genannt) zum Einsatz.
Crawler sind vollautomatische Tools, die in den meisten Fällen fortwährend Webquellen scannen und die Ergebnisse in einer Datenbank speichern. Crawler sind vor allem durch öffentliche und populäre Suchmaschinen wie Google bekannt.
Der Google-Crawler
Google setzt seinen eigenen Crawler namens „Googlebot“ ein, der ständig das Web durchsucht und allen Links folgt, die er auf Websites findet. Dadurch entsteht eine große Sammlung von Webinhalten, die schließlich über die Oberfläche der Suchmaschine gefunden werden können.
Wie funktioniert ein Crawler?
Dabei gehen die Crawler meist nicht vollständig in die Tiefe einer Website. Vor allem bei Foren verzichtet unter anderem Google auf eine komplette Indexierung, um die Datenmengen in der eigenen Datenbank geringer zu halten.
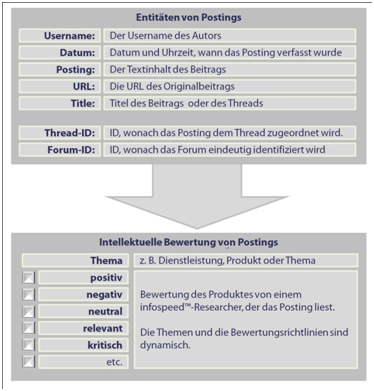
Die Datengewinnung aus Social-Media-Quellen stellt Crawler vor neue Herausforderungen. Ein gewöhnlicher Crawler kann Texte in großen Mengen erfassen und unstrukturiert in seiner Datenbank ablegen. Social-Media-Quellen enthalten jedoch sogenannte Entitäten. Als Entitäten werden in der Informatik und auch in Social Media Attribute wie „Autorenname“, „Datum des Beitrags“, und „Posting“ bezeichnet. Diese Eigenschaft erschwert dem Monitoring Crawler die Datengewinnung um ein Vielfaches, da er in diesem Fall in der Lage sein muss, die Strukturen in einer Social-Media-Quelle zu erkennen.
Social Media Automation
Das Ziel einer Social-Media-Monitoring-Technologie ist es, eine nach Entitäten strukturierte Datenbank bereitzustellen, um ein professionelles Retrieval zu ermöglichen.
Was bringt eine Automation?
Liegen die Entitäten in einer Datenbank nicht geordnet vor, lässt sich kein Mehrwert gegenüber Suchmaschinen wie Google erkennen. Erst durch die Erkennung von Entitäten können spezielle Suchen durchgeführt werden, die beispielsweise nach den aktivsten Usern in einem bestimmten Themenbereich fahnden. Auch zeitliche Suchen sind erst möglich, wenn in der strukturierten Datenbank Datum und Uhrzeit eines Beitrags vorliegen. Gerade diese sind jedoch nicht leicht zu identifizieren. So muss die Social-Media-Monitoring-Technologie zwischen dem Registrierungsdatum des Users (beispielsweise „registriert seit“), einem Termin innerhalb des Beitrags (zum Beispiel ein Veranstaltungstermin, auf den der User aufmerksam macht) und dem Zeitpunkt, zu dem der Beitrag gepostet wurde, unterscheiden können.
Automation-Technologien im Monitoring
Hierzu setzen Anbieter verschiedene Technologien ein. Eine Möglichkeit ist es, Daten erst unstrukturiert zu gewinnen und dann mit Hilfe eines komplexen Datenbereinigungsprozesses auf Strukturen zu untersuchen. Diese Methode führt jedoch aufgrund ihrer Komplexität häufig zu hohen Rechenleistungen. Gleichzeitig sorgt die hohe Fehlerquote nur für unbefriedigende Ergebnisse.
Indexierung durch „Scraping“
Eine andere, wesentlich effizientere Möglichkeit der Datengewinnung kann das Scrapen sein. In diesem Fall versucht ein Crawler bereits während der Datensammlung die Struktur in den Social-Media-Quellen zu erkennen. Erst wenn Strukturen korrekt identifiziert worden sind, werden die Daten gespeichert. Erfolgt keine eindeutige Erkennung, setzt der Crawler seine Indexierung nicht fort und alarmiert gegebenenfalls den Administrator.
Strukturen besser erkennen
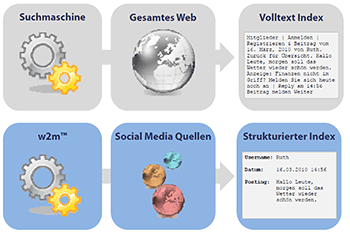
Da mehr als 90% aller Social-Media-Inhalte unstrukturiert sind, setzt diese Methode die wahrscheinlich größte innovative Anstrengung voraus. Zur Erkennung unstrukturierter Daten im Social Web sind meist informationswissenschaftliche Kenntnisse und anwendungsorientierte Informatik nötig. Diese Art führt jedoch zu deutlich weniger Fehlern in der Datenbank. Hierbei muss die Monitoring-Technologie Entitäten nicht erst durch einen aufwändigen Prozess identifizieren: Die entstehende Datenbank wäre dann im besten Fall bereits optimal strukturiert.
Social Media Entitäten
Falsch zugeordnete Entitäten können die Suchmaschine etwa dazu bringen, Autoren, Beiträge und Datumsnennungen zusammenzumischen. Die Identifikation von Meinungsführern wird so erschwert oder gar ganz verhindert. Data Mining und Analysen werden erst durch eine korrekte Erkennung der Attributwerte möglich.
Eine Monitoring-Agentur ist in der Lage, Auskunft darüber zu geben, ob eine Indexierung stattfindet. Findet keine statt, sollte hinterfragt werden, wie die Agentur an ihre Daten gelangt. Werden sie beispielsweise eingekauft, liegt die Überlegung nahe, die Dienstleistung direkt beim Daten-Anbieter zu beziehen.
Social Media Index

Es ist eigentlich unabdingbar, dass eine Monitoring-Agentur Foren selbst indexiert und diese Indexierung mit Hilfe eines elaborierten Prozesses und mit technischem Know-how durchführt.
Eine größere Monitoring-Agentur kann grundsätzlich alle drei Varianten der Datenerfassung anbieten. Die Möglichkeit der eigenen Indexierung hat jedoch Priorität. Die Indexierung unstrukturierter Daten aus dem Web ohne die Unterstützung von APIs ist sicherlich die fortschrittlichste und gleichzeitig schwierigste Form der Datengewinnung. Sie ist jedoch notwendig, da sonst die größte Menge an Social-Media-Quellen nicht ausgewertet werden kann. Der gleichzeitige Einsatz von Schnittstellen gewährleistet, dass weitere Quellen einfach und schnell ausgelesen werden können. Die Kombination aller drei Möglichkeiten stellt Social Media Monitoring zwar vor diverse informationswissenschaftliche Herausforderungen, macht aber letztlich einen kompetenten Monitoring-Dienstleister aus.
Als empfehlenswert kann ein Anbieter bezeichnet werden, der sowohl die verwendeten Daten selbst indexiert, als auch die Dienstleistung des Social Media Monitoring anbietet. Auf diese Weise können Kundenwünsche wie das Hinzufügen neuer Quellen zeitnah umgesetzt werden.








